进阶
Flux 图像变体
在本章中,我们将介绍如何使用 Flux Redux 生成相似的图像。

本图由 AI 生成

1. 下载 Flux Redux 模型
首先第一步,还是要下载 Flux Redux 模型。你需要去到这里下载 Flux Redux dev 模型,并将其放在/models/style_models 目录下,注意是 style_models 目录,而不是 diffusion_models 目录。
除了这个模型外,你还需要下载一个名为 sigclip_vision_patch14_384 的模型。这个模型是 Flux 用来将图片转为 Conditioning 的模型。你需要去到这里下载此模型,并将其放在 /models/clip_vision 目录下。
2. Flux Redux 基础工作流
2.1 单图变体
下载好模型后,我们来搭建 Flux Redux 的 ComfyUI 工作流。 如果你不想手动连接,可以去 Comflowy 下载此工作流模板,并导入到本地 ComfyUI 使用。(另外,如果你不知道如何下载 Comflowy 模板,可以参考此教程)Flux ComfyUI 工作流模板
点击右上角 Remix 按钮,进入 ComfyUI 工作流模式。
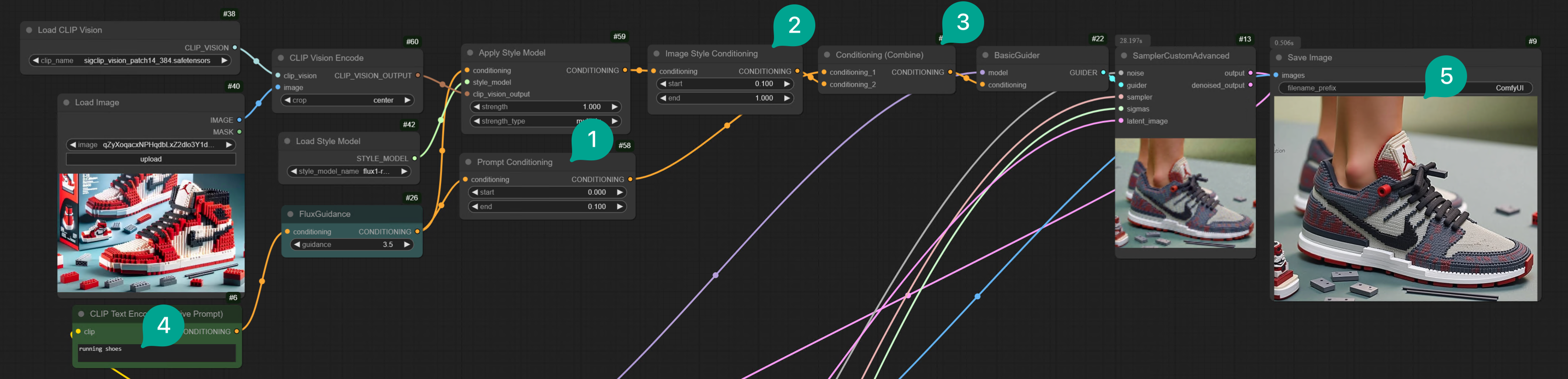
Apply Style Model 节点(图中①),然后这个节点输出是 Conditioning,所以需要跟 BasicGuider 节点相连。
然后这个 Apply Style Model 节点有以下几个输入节点:
- Conditioning:正如我前面提到的那样,Redux 是将 Prompt 和图片一起输入到 Conditioning,所以这个 Conditioning 需要跟 CLIP 后的 FluxGuidance 节点相连。
- Style Model:这个就是要连 Flux Redux 模型,双击空白处,搜索
Load Style Model节点(图中②),然后添加到工作流中,然后将其和Apply Style Model节点相连,并选择我们前面下载好的 Flux Redux 模型。 - Clip_vision_output:搜索
Clip Vision Encode节点(图中③),然后添加到工作流中,然后将其和Load CLIP Vision节点(图中④)以及Load Image节点(图中⑤)相连。
这里需要注意,图中③的
Clip Vision Encode 有个额外的 crop 参数。这是什么意思? 它会对你的图片进行裁剪,然后只对裁剪后的图片进行编码。如果你选择 Center 就意味着会裁切图片的中间部分。为何需要裁切?因为 Redux 模型只能接收方形图片。所以你的输入图最好是正方形,不然最后生成的图可能不会包含里图片里的所有元素。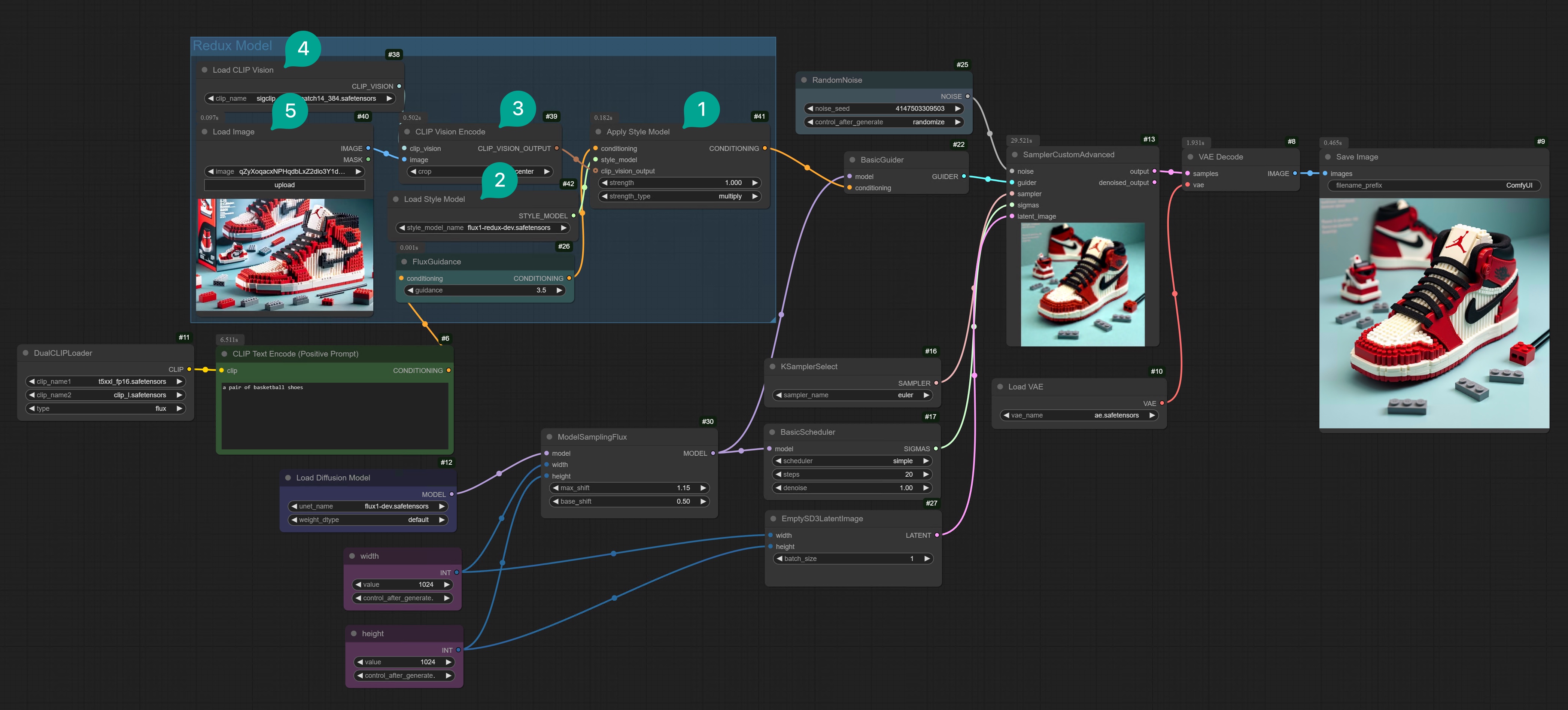
sigclip_vision_patch14_384 的模型将图片转为 Vision(简单理解就是一堆词向量),然后再用 Redux 模型将 Vision 数据转为 Conditioning(简单理解就是转为 Flux 能理解的向量),然后将其和 Prompt 一起输入到 Flux Redux 模型中,最后将 Flux Redux 模型的输出和原图一起输入到 Flux 模型中,生成出图片。
简单理解可以将这个过程理解为,用 Flux Redux 模型就像一个翻译。它将图片里的各种元素翻译成 Flux 模型能理解的 Conditioning 数据,然后再输入到 Flux 模型中生成出图片。
2.2 两图融合
除了可以用单张图生成变体外,你还可以试试将两张图通过 Redux 模型融合在一起。基于上面的工作流,我们只需要增加一个Batch Images 节点(图中①),然后将其和第二个 Load Image 节点(图中②)相连。
然后选择两张你想要融合的图片,比如我是将一张沙发和一张森林的图片融合在一起,你将会得到了一张很有意思的图片。
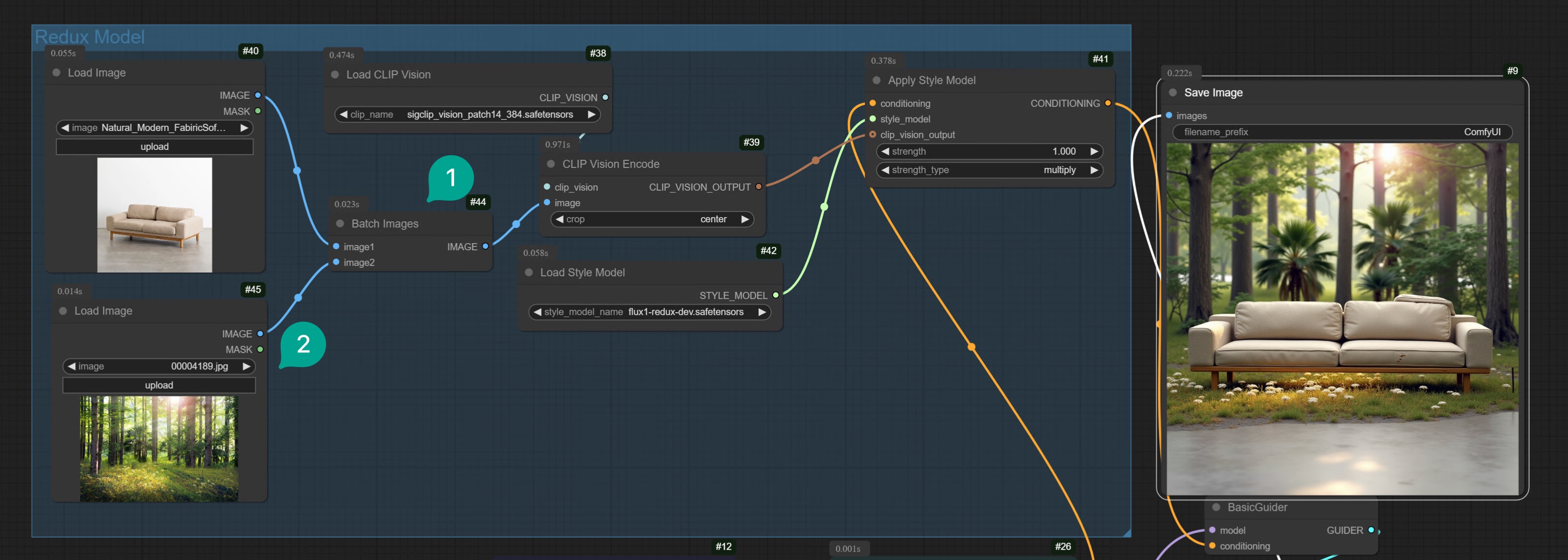
Flux ComfyUI 工作流模板
点击右上角 Remix 按钮,进入 ComfyUI 工作流模式。
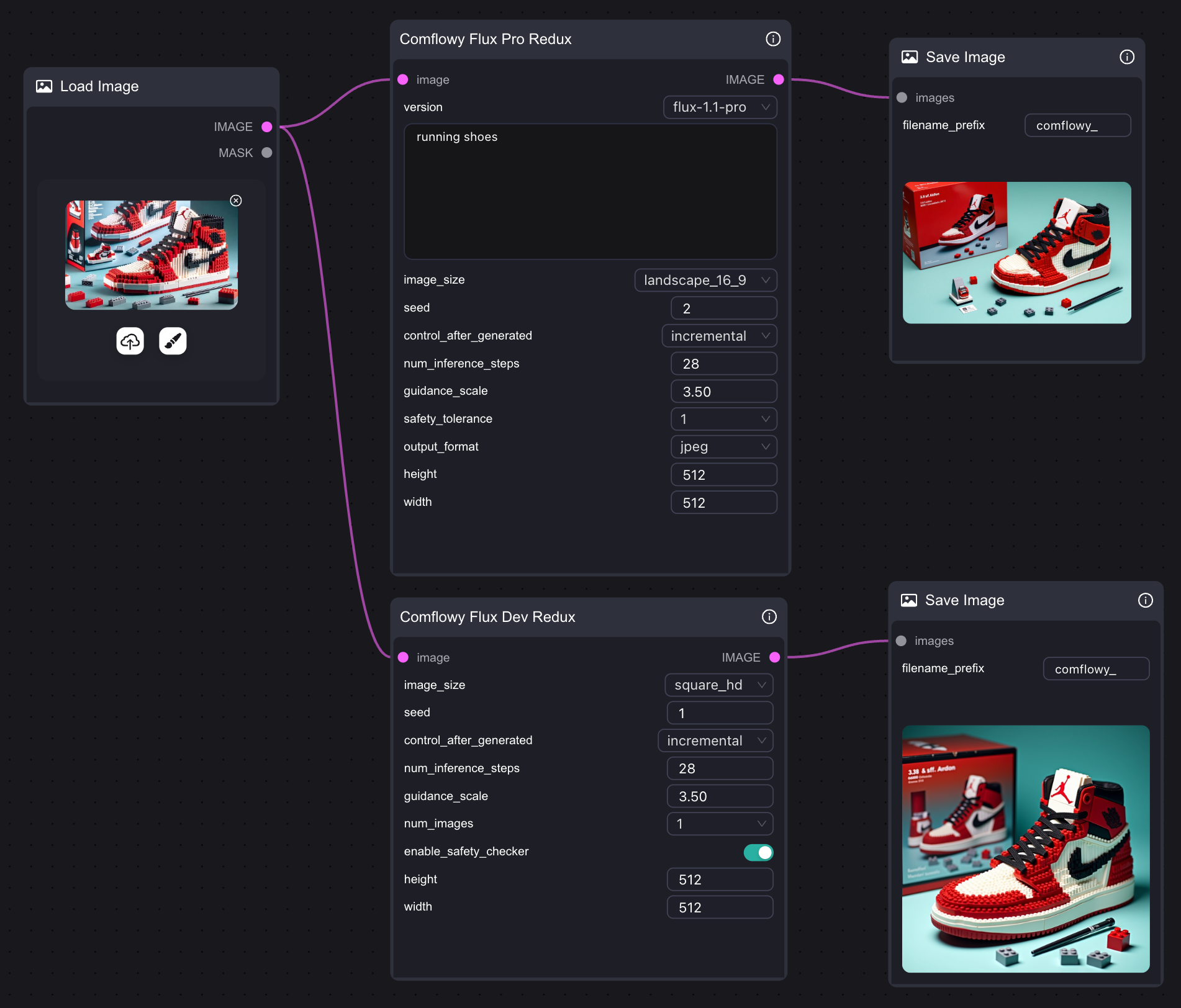
3. Flux Redux API 工作流
如果你的电脑性能不够,无法跑动 Flux Redux 模型,也可以试试在 ComfyUI 里使用 Comflowy 的 Redux API 节点。当然,你也可以直接在 Comflowy 里使用 Flux Redux API 节点,链接方式很简单,只需要用一个节点就能使用,同时还支持 Flux Pro 版本和 Dev 版本.注意,因为此节点使用的是 API,所以使用的时候需要支付相应的费用。
4. 降低 Flux Redux 权重
在使用上面的工作流的时候,你可能会发现,Prompt 的权重极低,你基本上无法通过 Prompt 去更改图片的内容,亦或者是风格。这是什么原因? 前面提到了 Flux Redux 模型就像一个翻译。它将图片里的各种元素翻译成 Flux 模型能理解的 Conditioning 数据,然后再输入到 Flux 模型中生成出图片。这些翻译的数据,会添加到你的 Prompt 后面。 但是因为你写的 Prompt 通常非常简短,一般在 255 或 512 个 token。相比之下,Redux 为你 Text 的 Prompt 长达 729 个 token。这可能是你原始 Prompt 的 3 倍。 那如果我想更多地通过 Prompt 去控制图片的内容,该怎么办?从数学的角度看,方法有两种:- 减小 Redux 的权重,或者说缩短 Redux 的 Prompt 长度。
- 增加 Text 的权重,或者说增加你 Prompt 的长度。
4.1 通过插件降低 Redux 权重
首先,先说第一种方法。为了解决这个问题,有开源开发者开发了这个插件,允许你更好地对 Redux 模型进行控制。 你可以通过 ComfyUI Manager 安装此插件,亦或者通过 Git Clone 的方式安装。详细的安装方式,可以参考安装 ComfyUI 插件一文。 安装完插件后,只需要修改工作流里的 Redux 的节点组:- 去掉
Apply Style Model节点。换成图中 ① 的Redux Advanced节点。 - 修改 Text Prompt。
- 最后你就能得到一个和输入图相似,但内容由 Text Prompt 控制的图片。比如下方案例,就是从乐高风格的篮球鞋,转化成了乐高风格的跑鞋。
- 你需要调整图中 ① 的
Redux Advanced节点 的downsampling_factor参数。这个参数的值越大,Image Prompt 的权重越低。3 大概是 medium 的强度。你可以根据自己情况测试一下各个值的效果。 - 除了调整
downsampling_factor参数外,你还可以调整downsampling_function参数。可以切换成不同的参数试试。
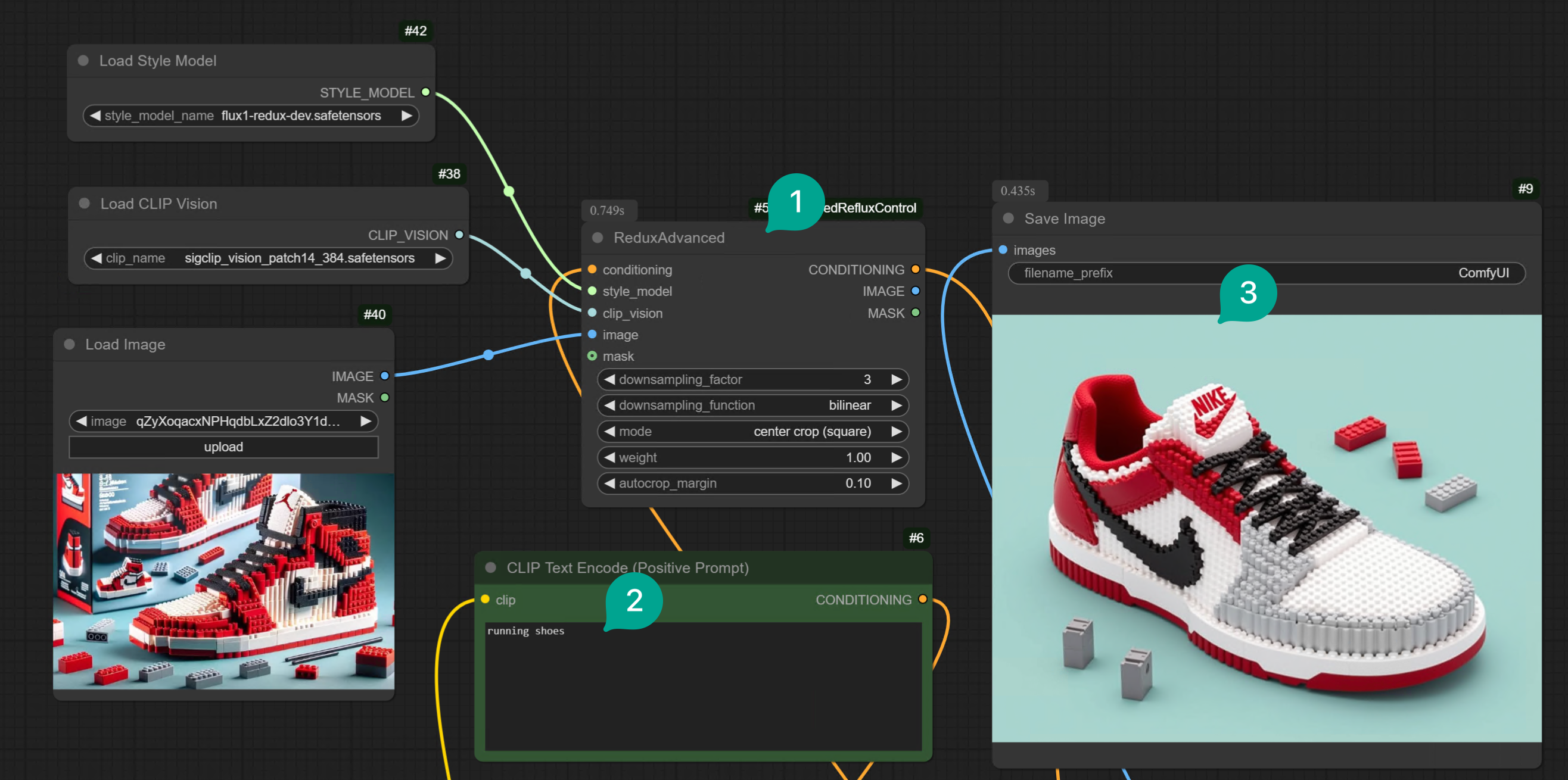
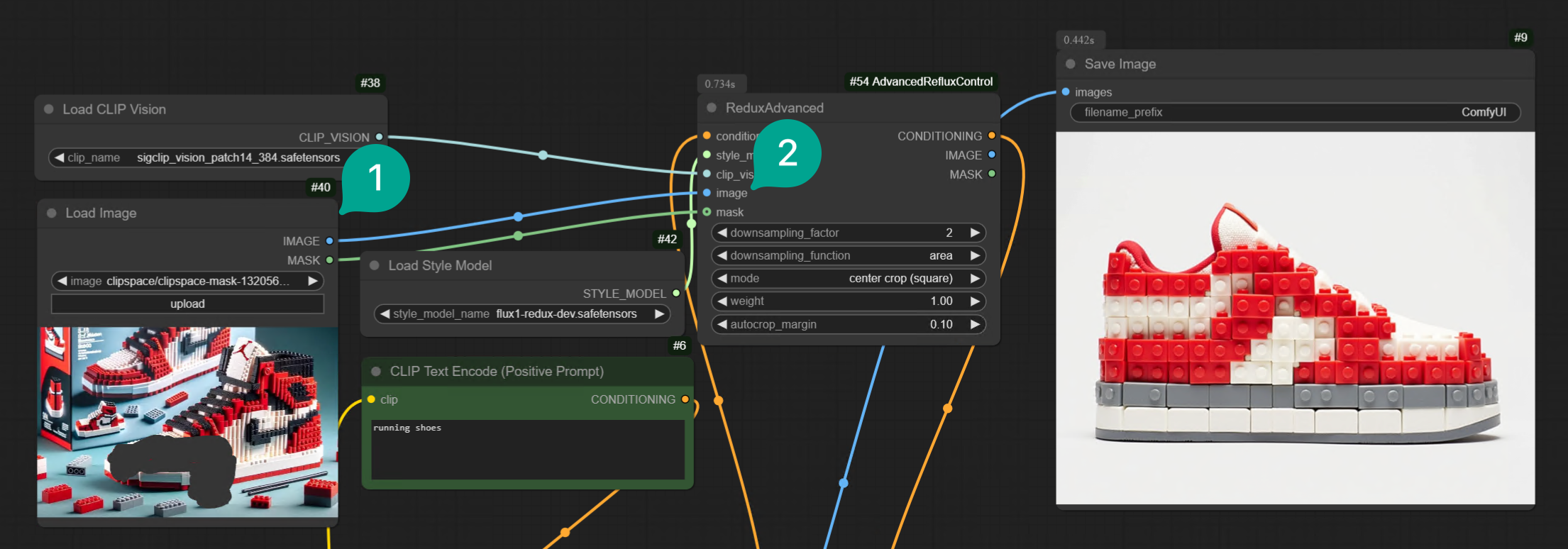
Load Image 节点的 Mask 端点与 Redux Advanced 节点里的 Mask 端点相连,然后圈定一些了一些区域:
4.2 增加 Text Prompt 权重
再说下第二种方法,增加 Text 的权重,或者说增加 Text Prompt 的长度。工作流如下: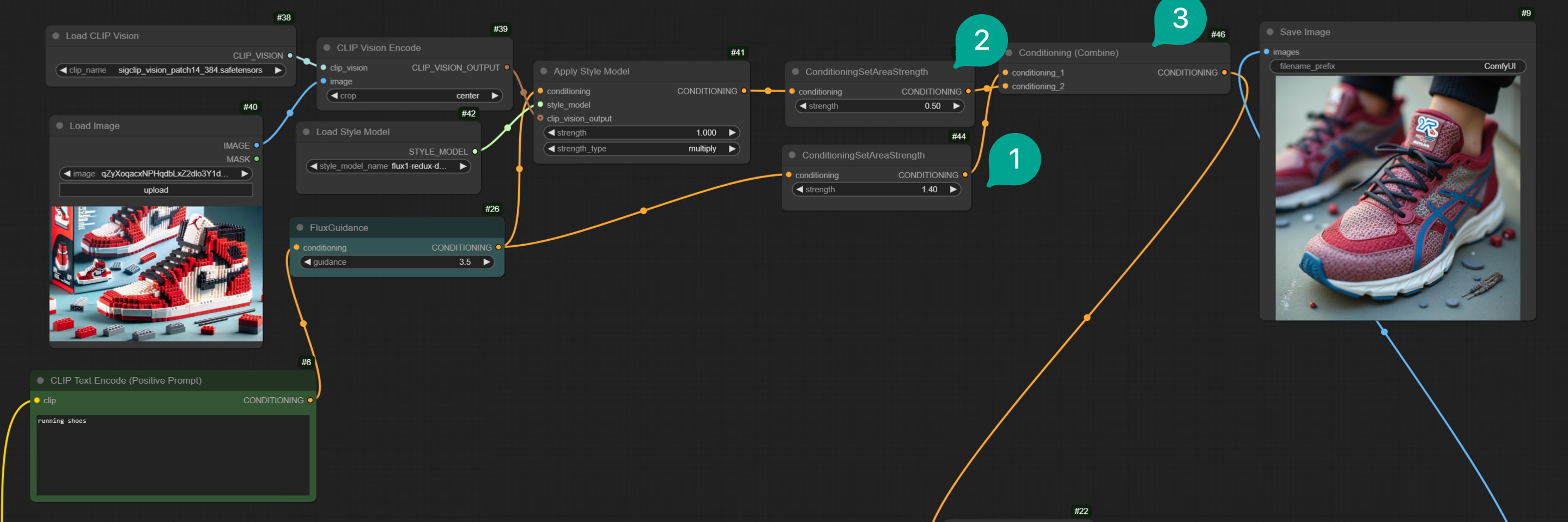
| 图示 | 描述 |
|---|---|
| ① | 我添加了一个ConditioningSetTimestepRange 节点,然后为了更好区分,我将它命名为 Prompt Conditioning。然后将其和 FluxGuidance 节点相连。并设置 start 为 0,end 为 0.1。这就意味着最后生图的过程中,Text Prompt 的占比会达到 10%。如果你想让 Prompt 权重更高,你可以将 end 的值设置得更大一些。 |
| ② | 再添加一个ConditioningSetTimestepRange 节点,然后为了更好区分,我将它命名为 Image Conditioning。然后将其和 Apply Style Model 节点相连。并设置 start 为 0.1,end 为 1。这就意味着最后生图的过程中,Image Conditioning 的占比会达到 90%。注意这里的 start 必须是大于 Prompt Conditioning 的 end 的值。 |
| ③ | 添加一个 Conditioning Combine 节点,然后将其和 Prompt Conditioning 以及 Image Conditioning 相连。 注意 Prompt Conditioning 是第一个输入。 |
| ④ | 然后我在 Text Prompt 里填写了 “running shoes” |
| ⑤ | 生成的图片主体就是 Running Shoes 了,但风格仍然是输入图的乐高风格。 |
需要注意,最后生成的图是否满足你的需求,取决于你如何分配
Prompt Conditioning 和 Image Conditioning 的占比,你可以根据自己的需要进行调整。