基础
Flux 模型介绍
本章节将介绍 Flux 模型,包括其版本、架构、使用方法和实现原理。
此图片由 AI 生成
1. Flux 模型概述
Flux 模型,全称为 FLUX.1,是由 Black Forest Labs 推出的一款前沿的文本到图像生成模型。 Black Forest Labs 是前 Stability AI 核心成员 Robin Rombach 创立的专注图像生成技术的公司,该公司刚创立就获得了 3200 万美元的融资。
Black Forest Labs 官网
1.1 模型版本
Flux 模型包含三个版本,分别是 FLUX.1 Pro、FLUX.1 Dev 和 FLUX.1 Schnell,以满足不同的使用场景和需求。- FLUX.1 Pro:闭源模型,提供最佳性能,适合商业应用。目前你仅能通过 API 的方式使用到它,或者使用调用该 API 的应用。
- FLUX.1 Dev:开源模型,不可商用,直接从 Pro 版本蒸馏而来,具有与 Pro 版本相似的图像质量和提示词遵循能力,但更高效。
- FLUX.1 Schnell:开源模型,基于 Apache 2.0 协议,专为本地开发和个人使用设计,具有最快的生成速度和最小的内存占用。
1.2 模型架构与差异
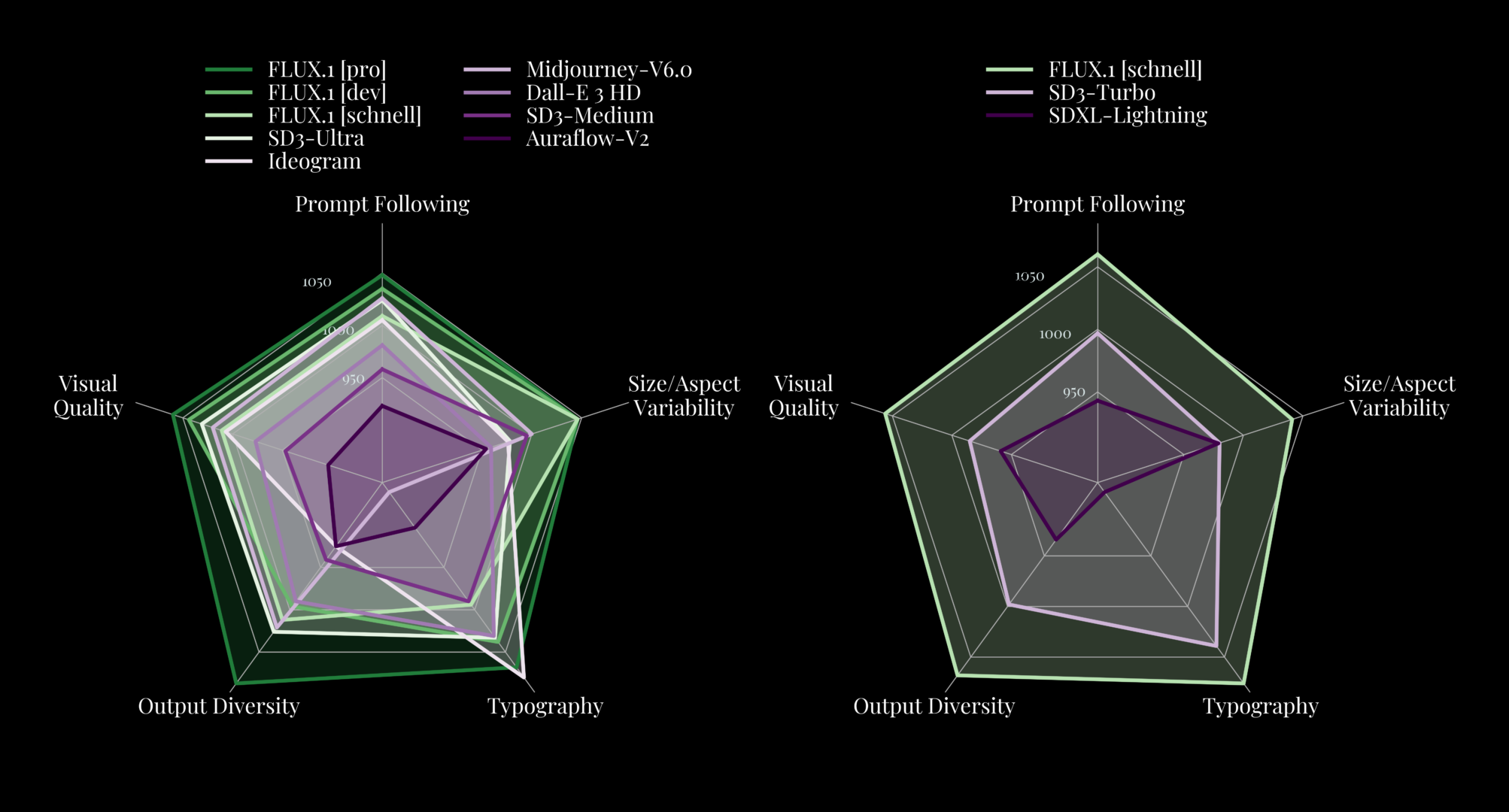
Flux 模型基于 Diffusion Transformer 架构,与主流的 Stable Diffusion 模型架构不同。在本章节后续的部分,我会详细介绍 Flux 模型架构。因为 Flux 采用了新的架构,所以它在图片生成的质量上,FLUX.1 [pro] 和 [dev] 在以下各方面均超越了 Midjourney v6.0、DALL-E 3 (HD) 和 SD3-Ultra 等流行模型,仅有在排版这一项落后 Ideogram:- 视觉质量(Visual Quality)
- 提示跟踪(Prompt Following)
- 尺寸/外观变化(Size/Aspect Variability)
- 排版(Typography)
- 输出多样性(Output Diversity)
1.3 使用方法
Flux 模型可以通过以下几种方式使用:- API:通过 API 的方式使用 Flux 模型。比如 Black Forest Labs 官方提供的 BFL API。
- Flux 应用:除了本地调用外,还可以在一些应用里使用 Flux 模型。比如 Comflowy 就提供了 Flux 各个版本的应用。如果电脑性能不佳,或无法安装 ComfyUI,可以考虑使用此方式。你可以前往 Flux 应用 页面,了解和使用 Flux 应用。
- 本地调用:你还可以通过 ComfyUI 在本地电脑使用 Flux 模型。如果你对 Flux 模型的实现原理不感兴趣,你可以直接查看以下章节,了解如何在 ComflyUI 里使用 Flux 模型。
Flux ComfyUI 工作流
了解如何在 ComflyUI 里使用 Flux 模型。
2. Flux 模型实现原理
如果你不想了解 Flux 模型的实现原理,想要看如何使用 Flux 模型,可以跳过此章节。另外,我也建议你在了解 Flux 模型架构之前,先了解下 Stable Diffusion 模型架构。你可以查看这篇教程:Stable Diffusion 模型基础。
2.1 回顾 Stable Diffusion 模型架构
正如前面所说,Flux 模型架构与 Stable Diffusion 不同,是基于 Diffusion Transformer 架构。所以,在介绍 Flux 模型架构之前,我先简单快速地介绍下 Stable Diffusion 的整体框架。 首先,用户输入文字指令,该文字指令会通过 Text Encoder 转为词向量,然后这些词向量会和 Random Image 数据进入到 Image Information Creator,通过一系列的降噪循环,得到图像的数据,最后这些数据通过 Decoder 转为人肉眼可见的图片。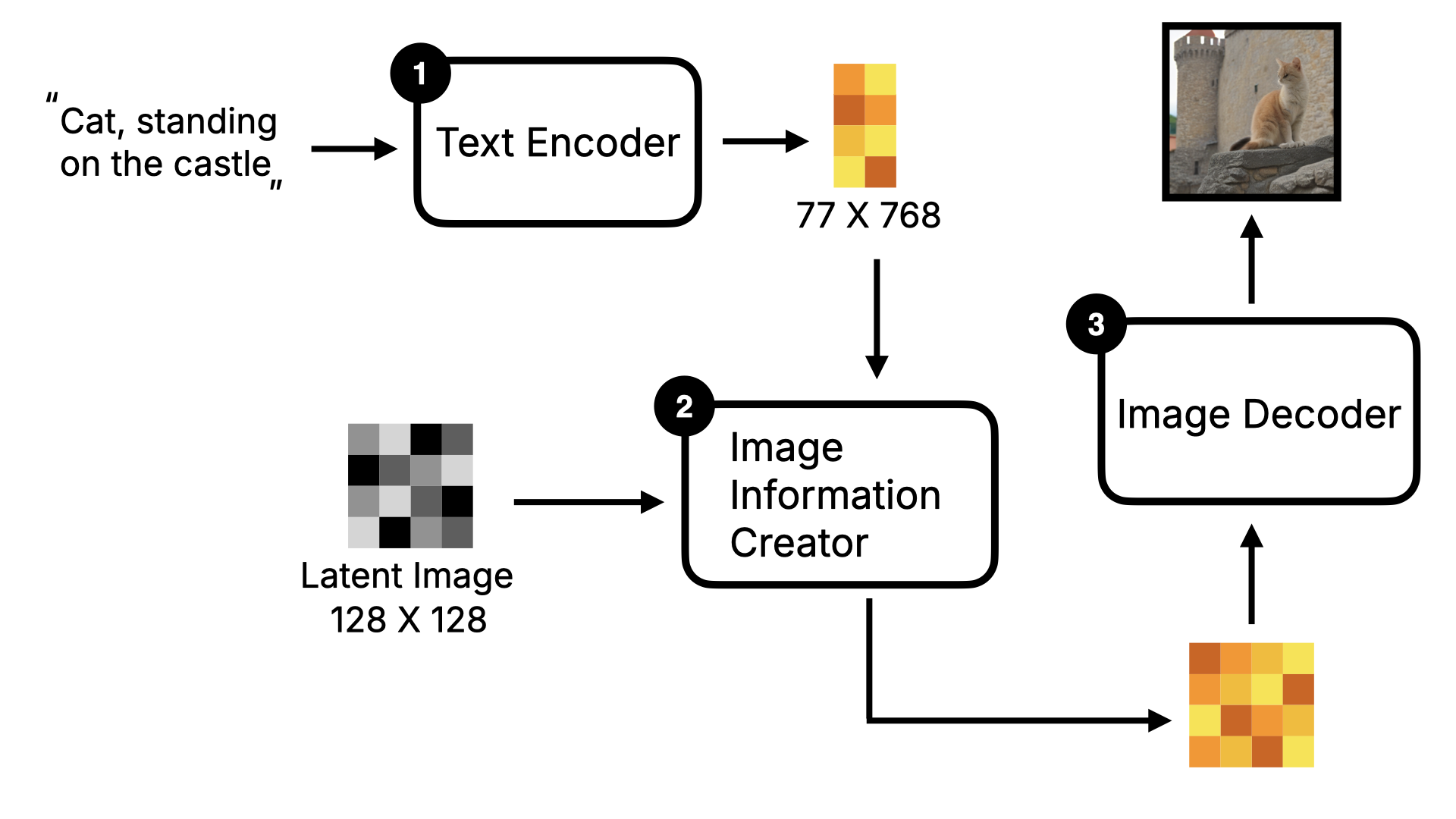
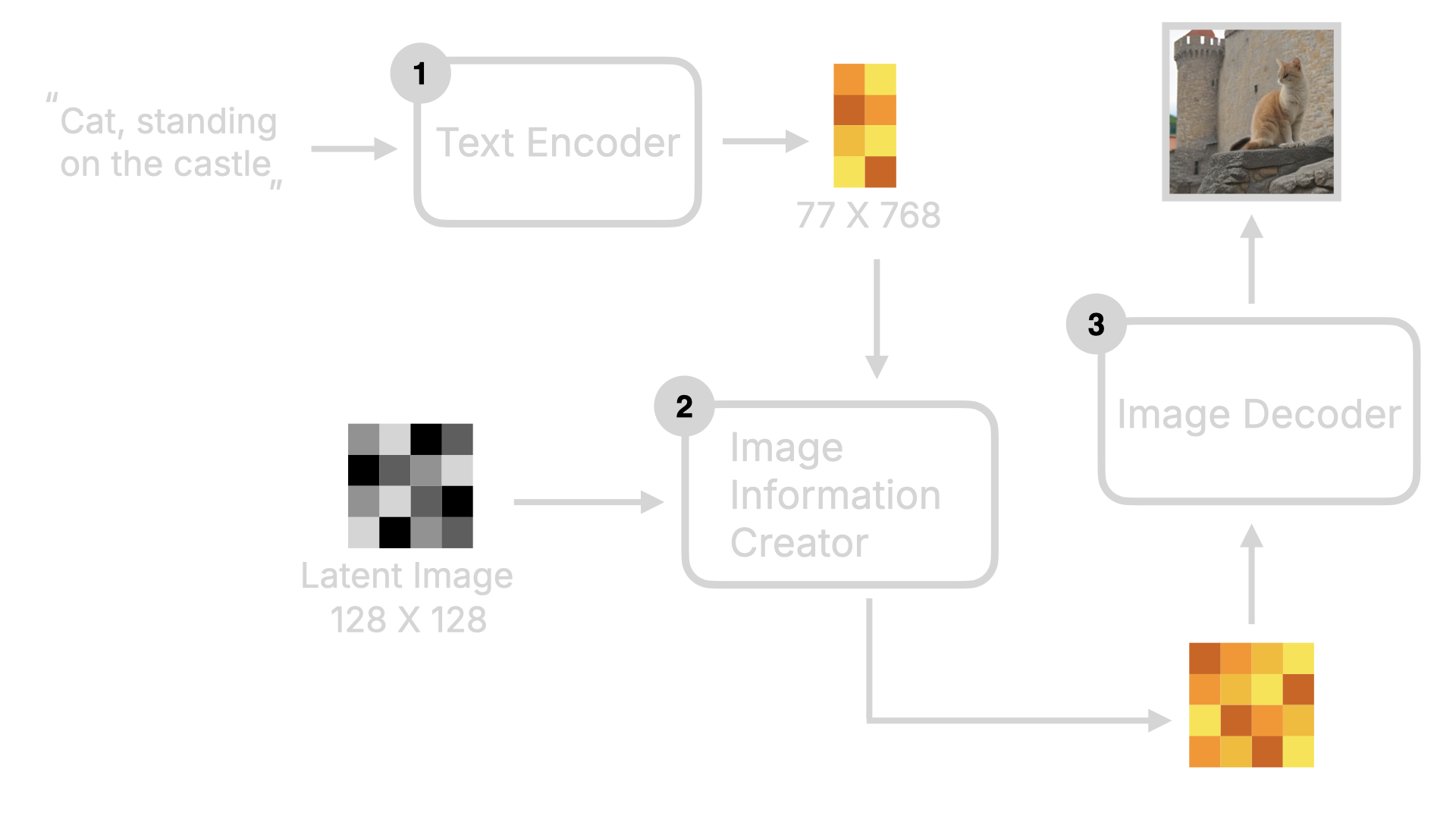
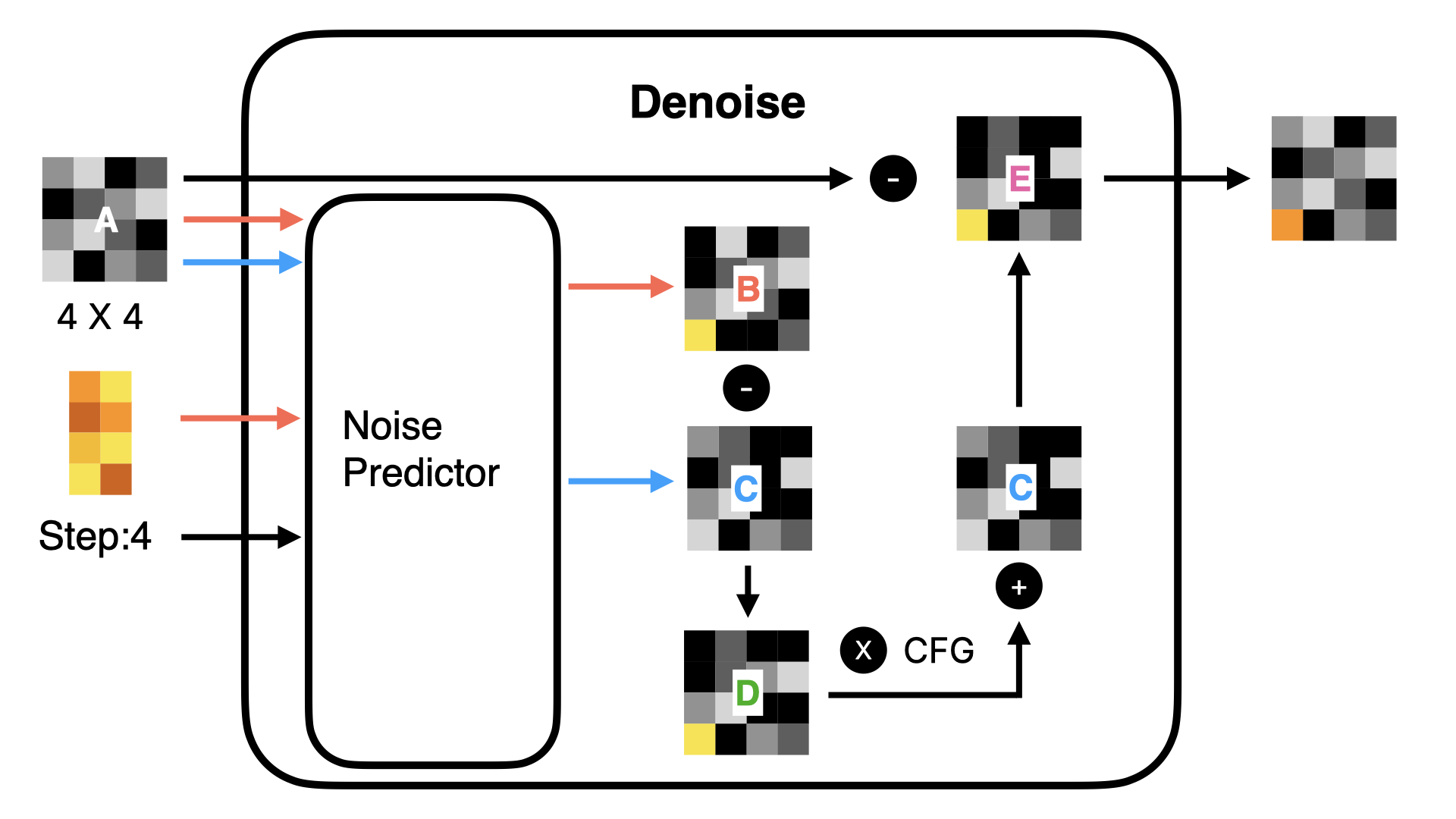
2.2 Flux 模型的关键变化
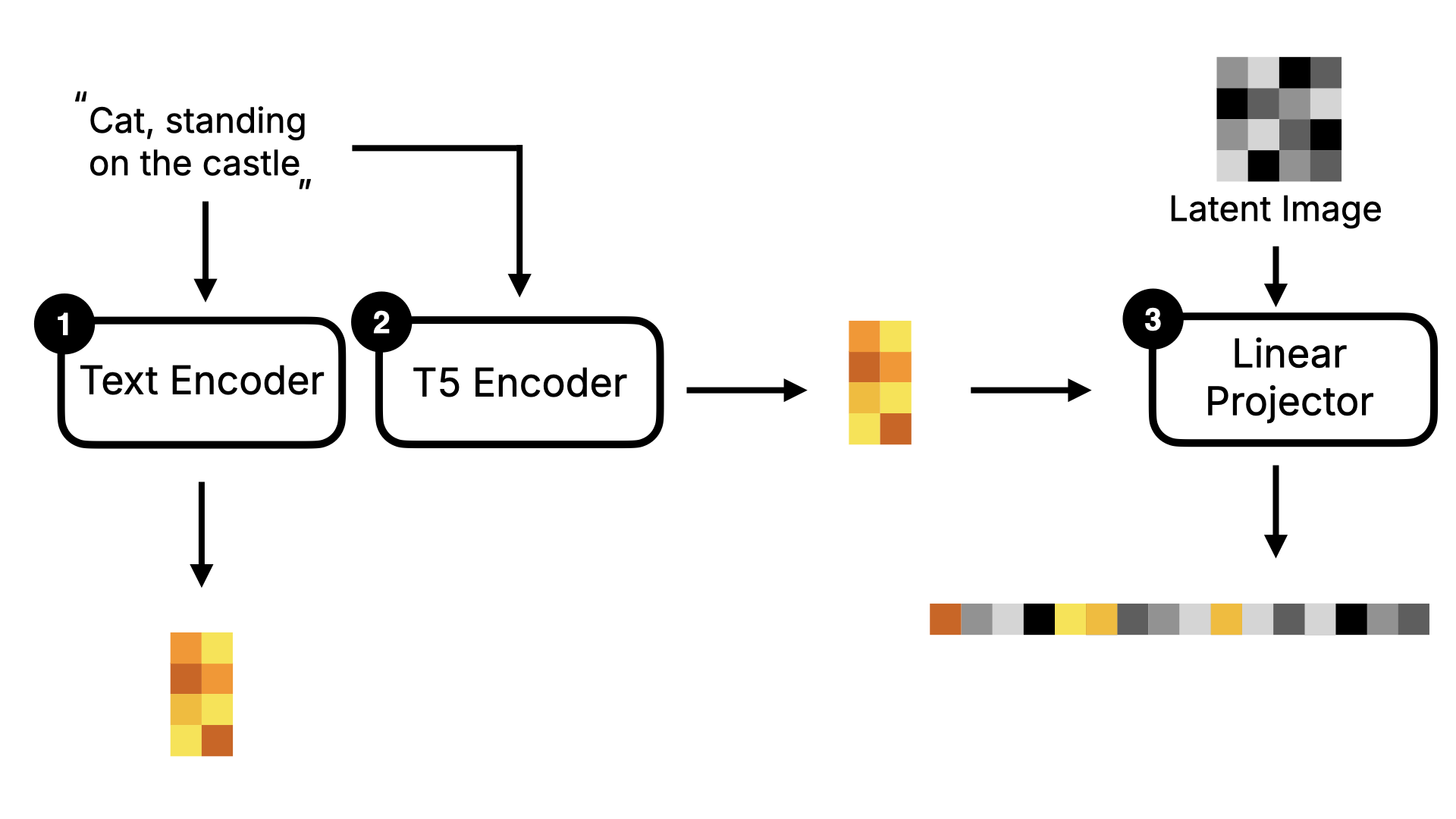
了解完 Stable Diffusion 后,我们再来看看 Flux 的实现。Flux 与 Stable Diffusion 最大的不同是它是一个 DiT (Diffusion Transformer)模型。DiT 模型最关键的不同是将原来 Diffusion 模型里的 U-Net 替换为了 Transformer。 我用以下这张图给大家解释下。整体框架来看,Flux 与 Stable Diffusion 类似,也会有 Text Encoder,Image Information Creator 以及 Image Decoder。但你可以看到,它比 Stable Diffusion 还多了一些东西,比如 T5 Encode,Linear Projector。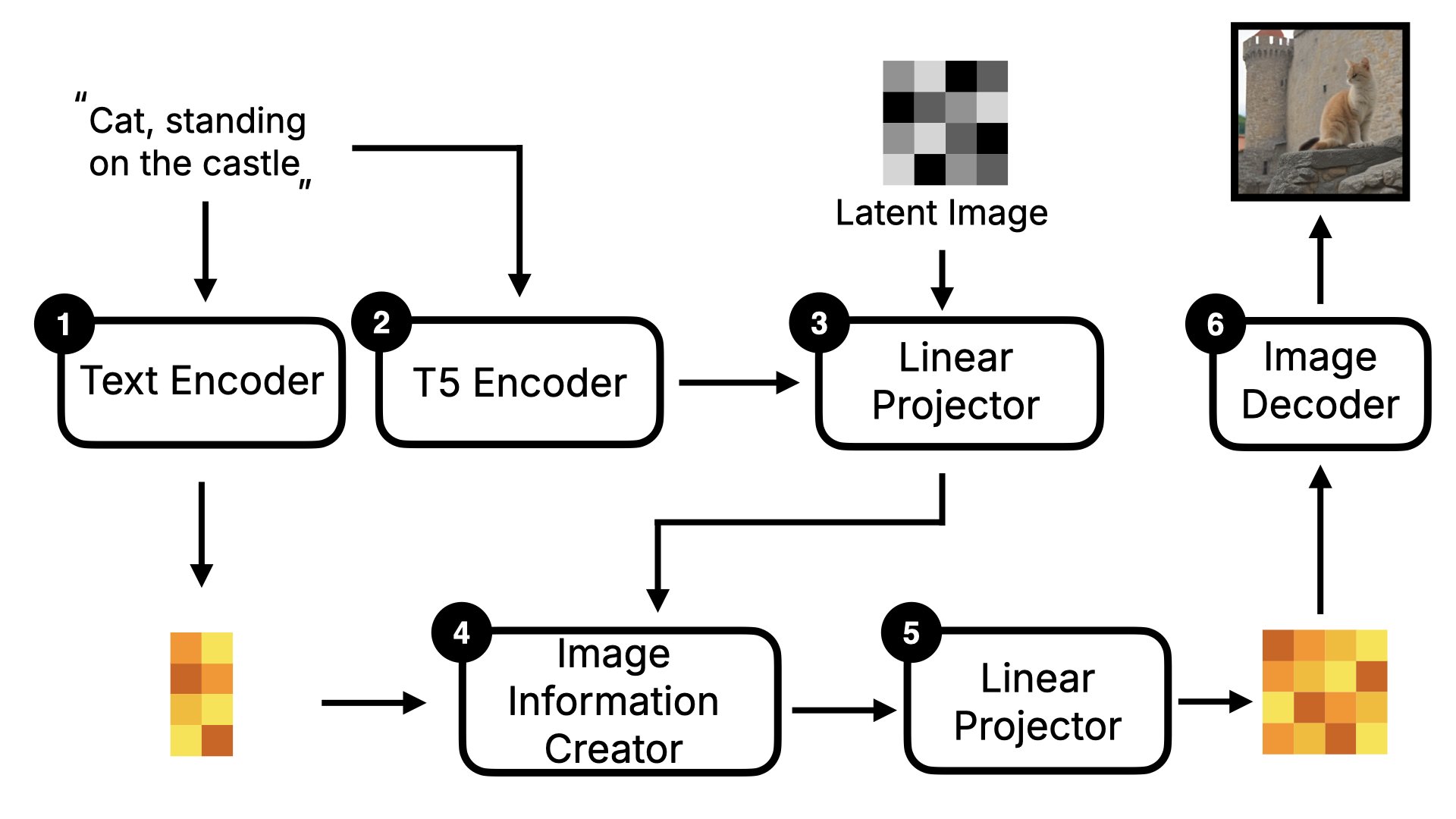
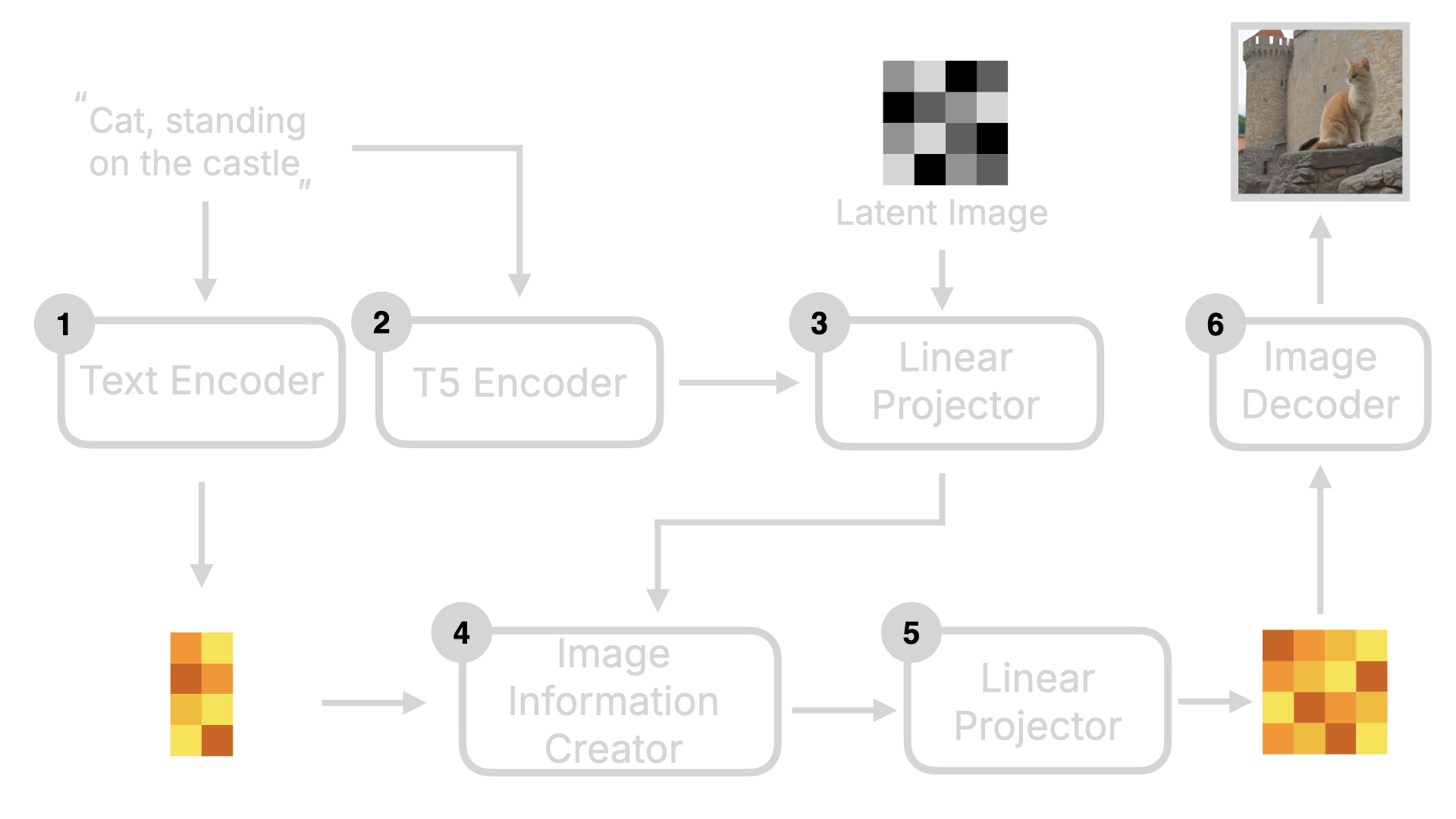
2.2.1 Diffusion Transformer
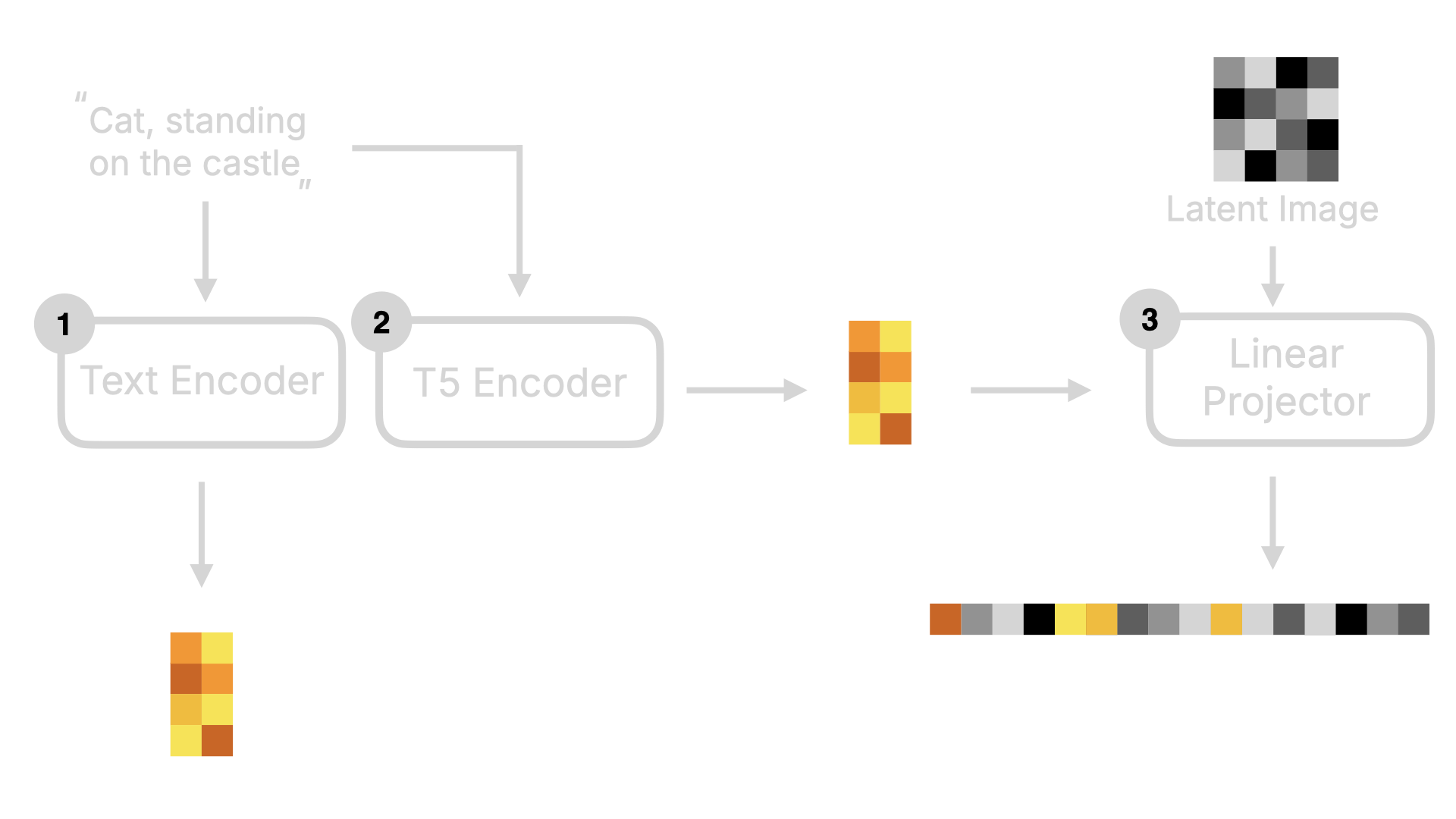
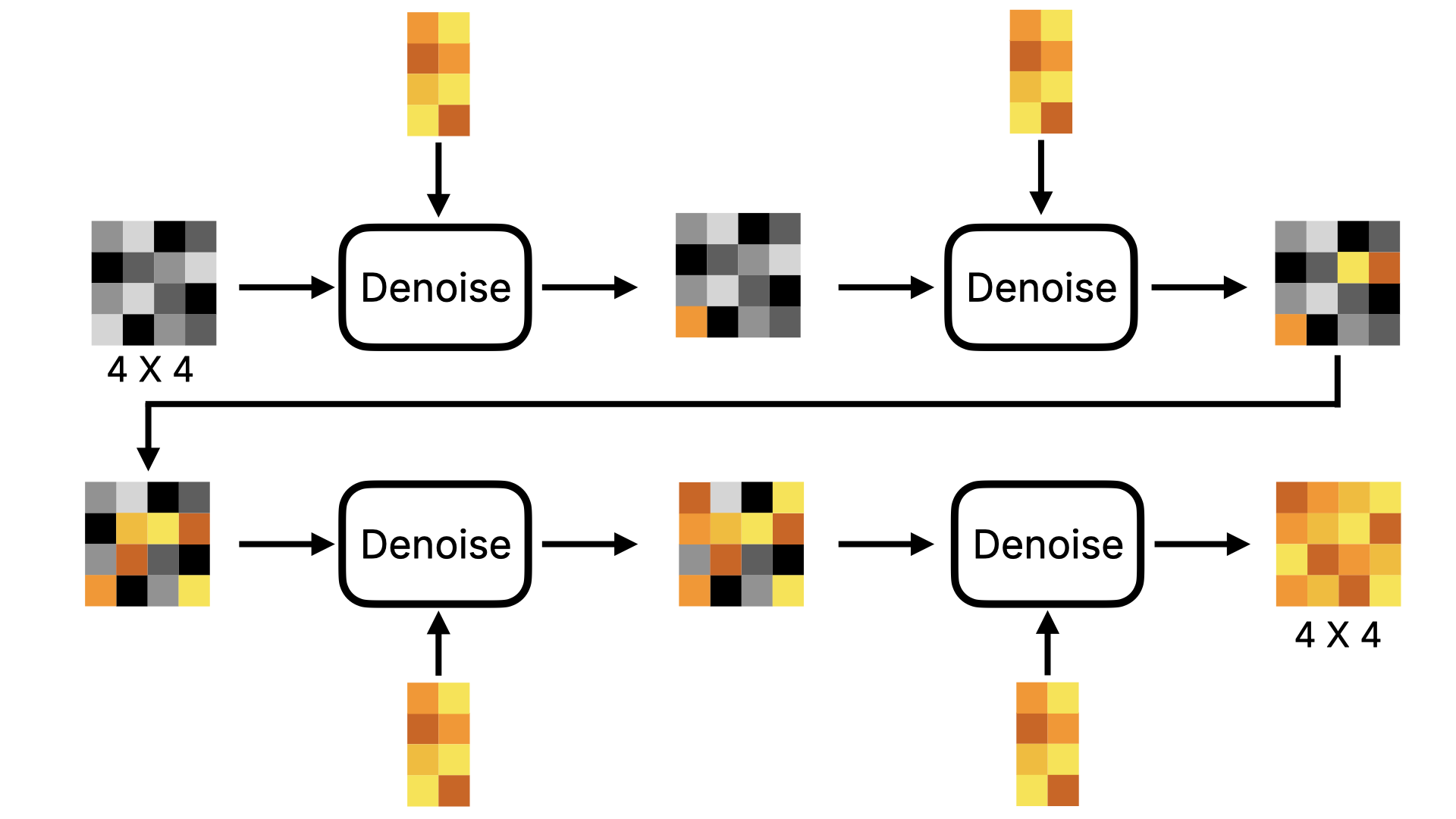
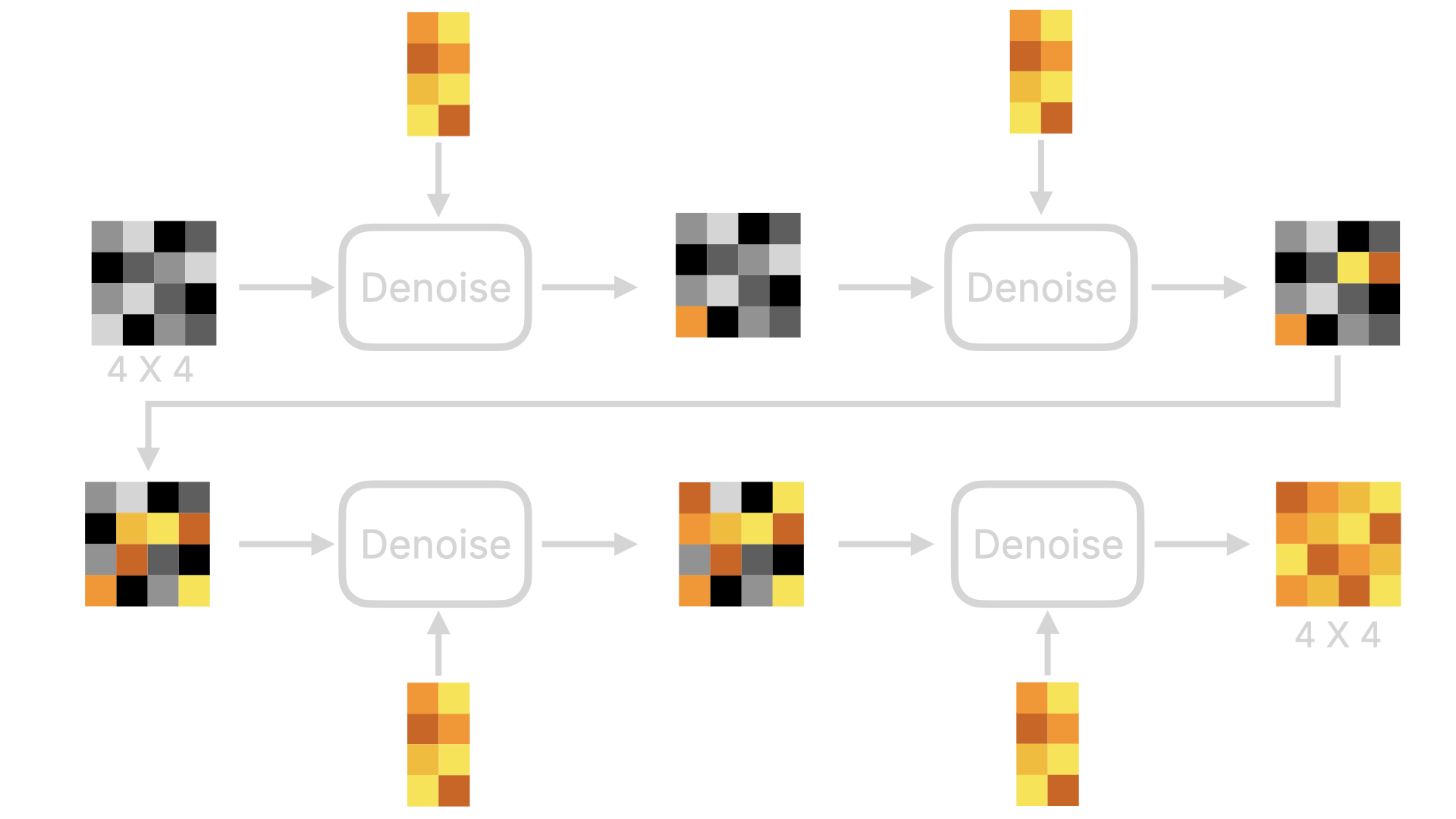
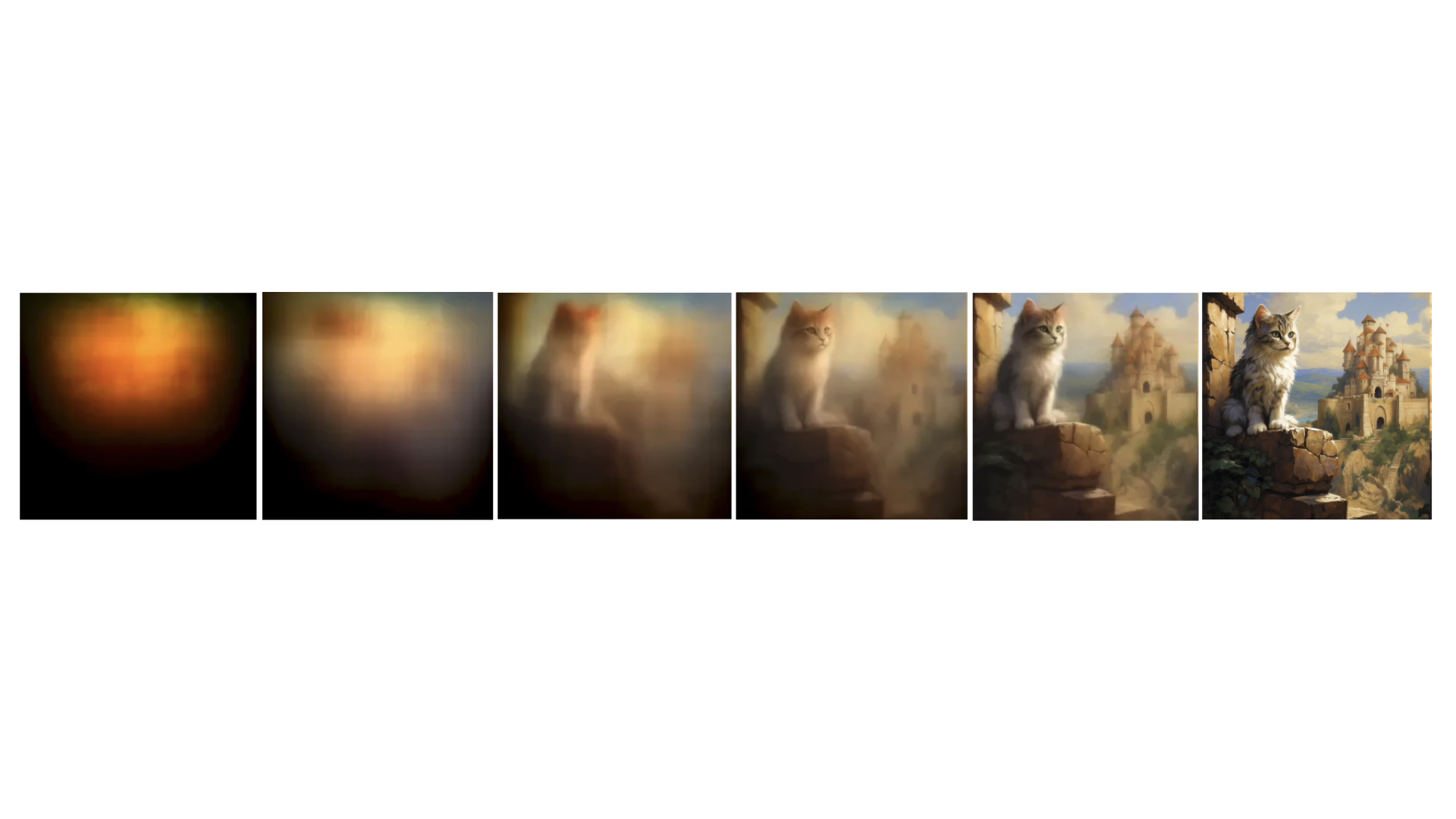
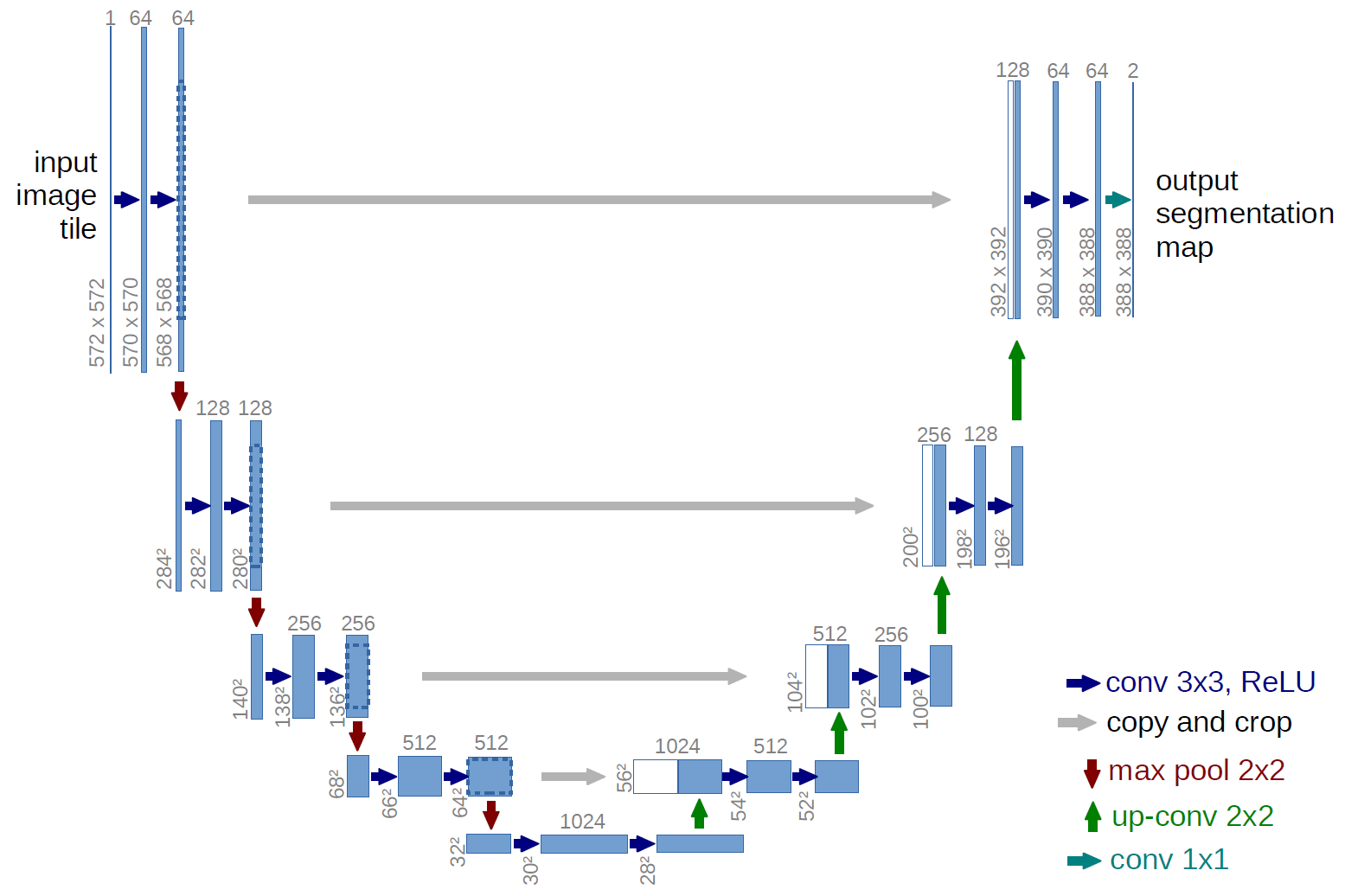
首先我们先来了解下 Linear Projector,这个环节是将二维的 Latent 数据转化为一维的 Token 数据。为何要这么做呢?因为在后续的降噪过程中(既图中的④),DiT 模型不再像原来的 U-Net 那样通过预测整张图的噪声的方式进行降噪。而是分块进行降噪。如果我们将这个过程进行可视化,会如下图所示:注意,我为了让图能表现出降噪的过程,所以图里都是肉眼可见的图,实际模型的情况是一维的数字,数字最终要经过 Image Decoder 才会转为人肉眼可见的图片。


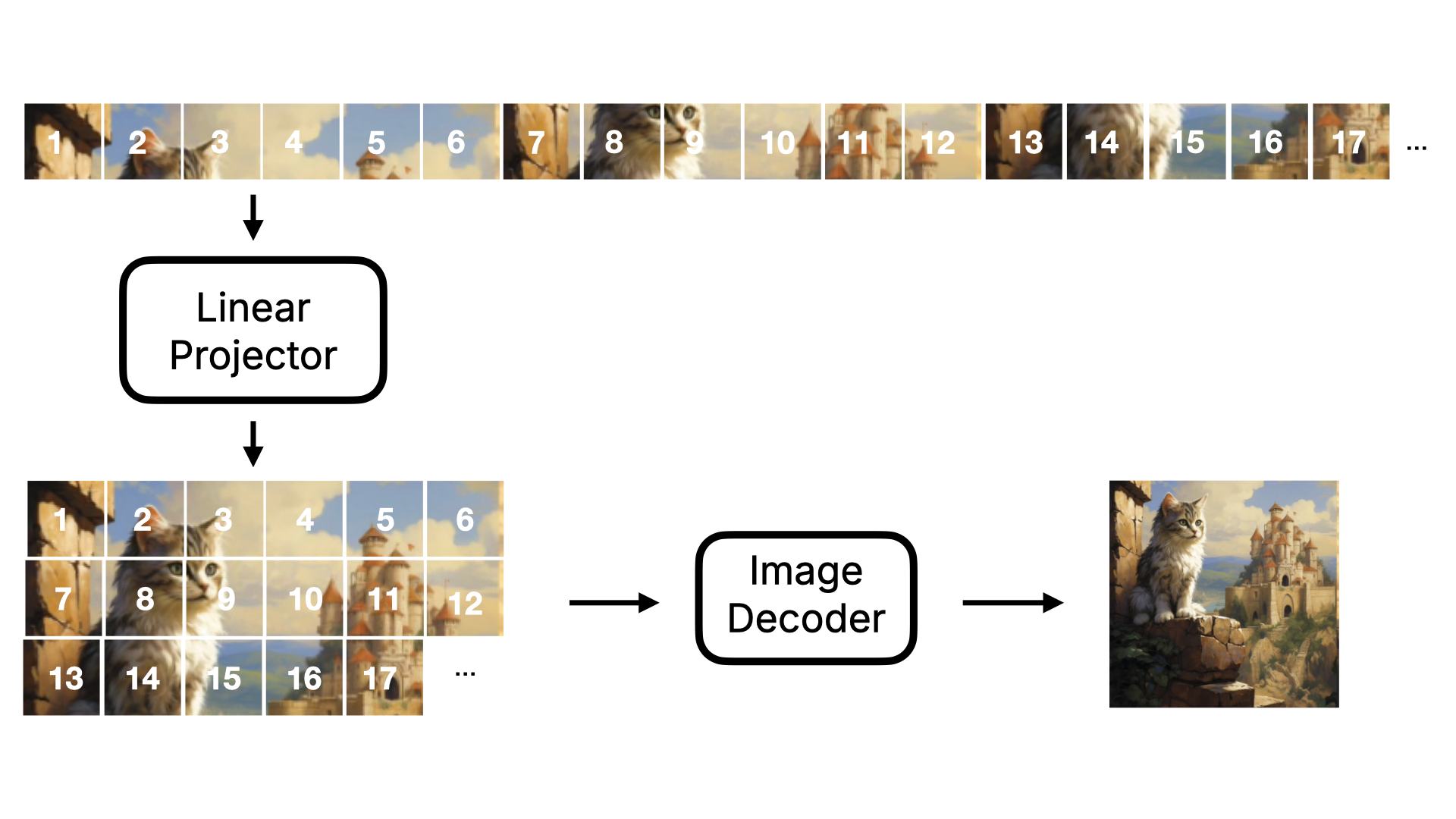
- U-Net 模型在预测噪音的时候,会对数据进行压缩和放大,在此过程中数据有可能会丢失。而采用这种 Transformer 的方式,少了压缩和放大,数据丢失的可能性会小很多。所以 Flux 模型在生成图片的细节才会比 Stable Diffusion 模型高。
- 另外,也得益于 Transformer 的向前注意力机制,在预测噪声的时候,可以带上前序图的数据进行预测,所以 Flux 模型在生成图片的连贯性上,也比 Stable Diffusion 模型要好。不会出现在某个位置出现不存在的物体。
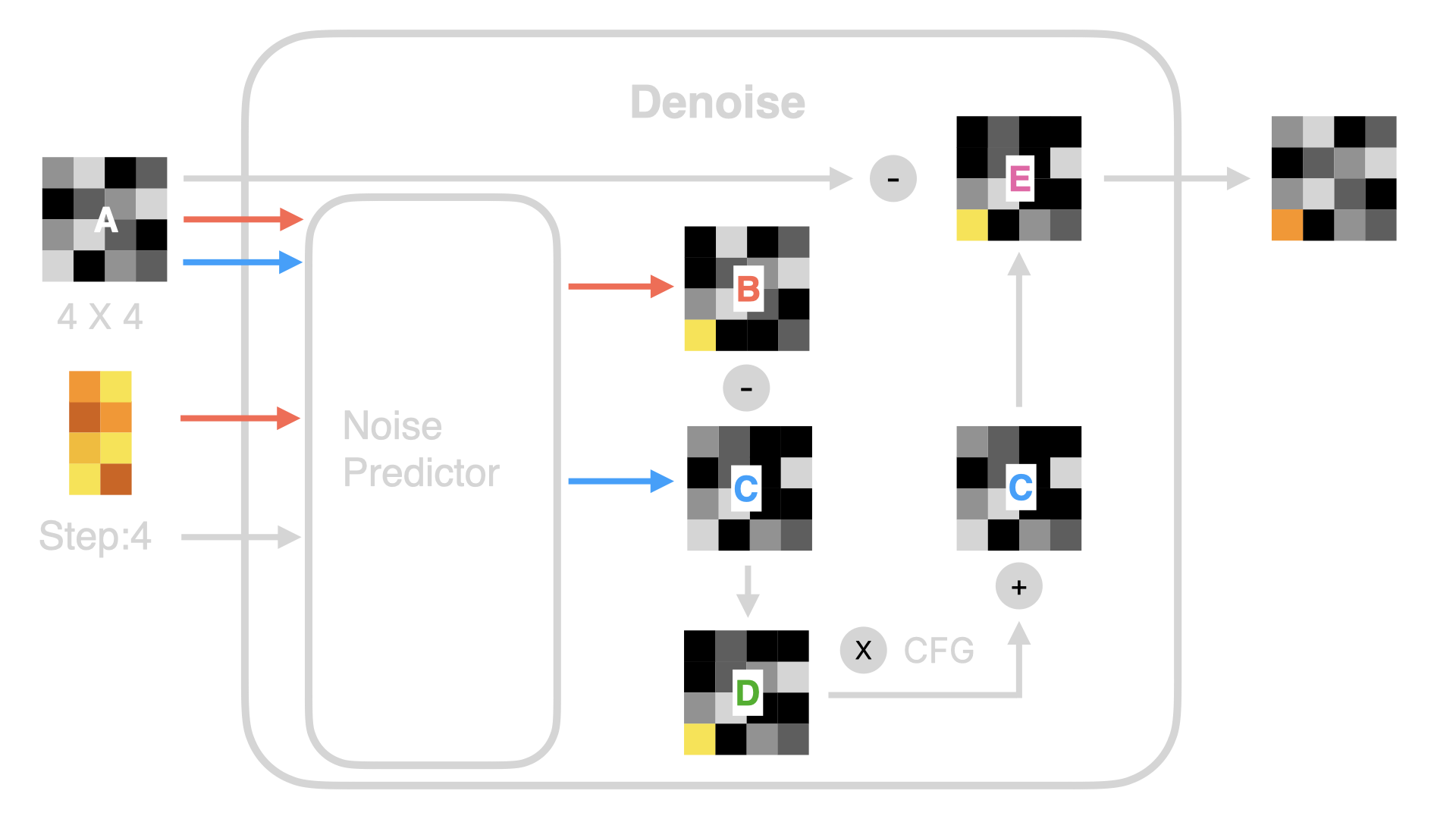
2.2.2 T5 Encoder
除了 Linear Projector 外,T5 Encoder 也是 Flux 模型的一个关键变化。T5 Encoder 是基于 T5 模型架构的文本编码器,它将文本指令转换为模型可以理解的词向量。然后这些词向量会和 Latent Image 数据一起进入到 Linear Projector 转化为一维的 Token 数据。同时这些数据还会被 Concat 到一起,作为降噪循环的输入。可视化的过程如下图所示: