この画像は AI によって生成されました

1. Flux Redux モデルのダウンロード
まず、Flux Redux モデルをダウンロードする必要があります。ここ から Flux Redux dev モデルをダウンロードし、/models/style_models ディレクトリに配置します。style_models ディレクトリであることに注意してください。diffusion_models ディレクトリではありません。
さらに、sigclip_vision_patch14_384 というモデルをダウンロードする必要があります。このモデルは Flux が画像を Conditioning に変換するために使用されます。ここ からこのモデルをダウンロードし、/models/clip_vision ディレクトリに配置します。
2. Flux Redux 基本ワークフロー
2.1 単一画像の変化
モデルをダウンロードしたら、Flux Redux ComfyUI ワークフローを構築します。 もし手動で接続したくない場合は、Comflowy からこのワークフローテンプレートをダウンロードし、ローカルの ComfyUI にインポートすることができます。(Comflowy テンプレートのダウンロード方法がわからない場合は、このチュートリアルを参照してください。)Flux ComfyUI Workflow Template
右上の Remix ボタンをクリックして ComfyUI ワークフローモードに入ります。
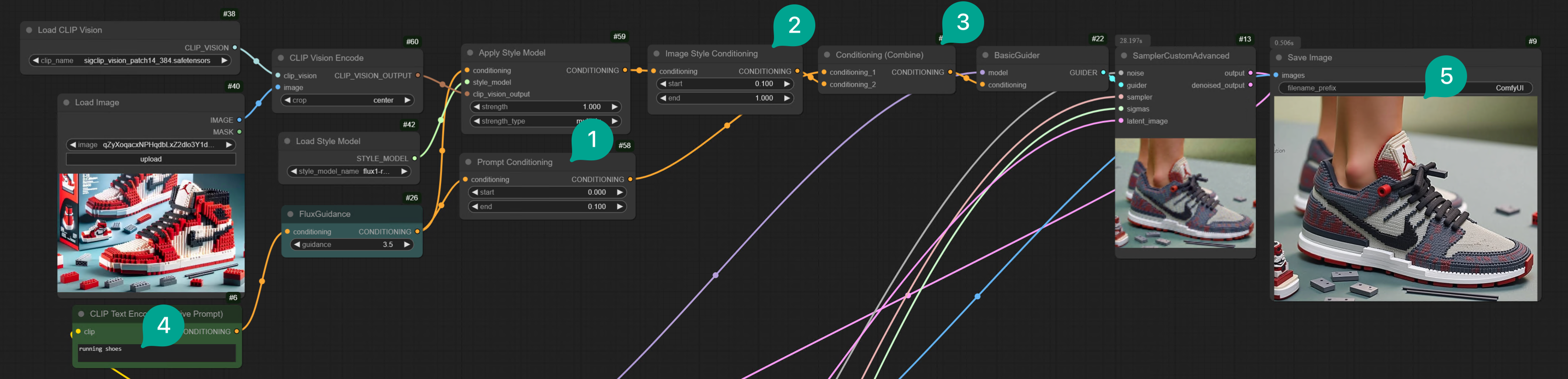
Apply Style Model ノード (図 ①) です。そして、このノードの出力は Conditioning であるため、BasicGuider ノードに接続する必要があります。
そして、Apply Style Model ノードには以下の入力ノードがあります:
- Conditioning: 前述したように、Redux は Prompt と画像を Conditioning に入力するため、この Conditioning は CLIP ベースの FluxGuidance ノードに接続する必要があります。
- Style Model: これは Flux Redux モデルに接続するためです。空白部分をダブルクリックし、
Load Style Modelノード (図 ②) を検索し、ワークフローに追加し、それをApply Style Modelノードに接続し、前述した Flux Redux モデルを選択します。 - Clip_vision_output:
Clip Vision Encodeノード (図 ③) を検索し、ワークフローに追加し、それをLoad CLIP Visionノード (図 ④) とLoad Imageノード (図 ⑤) に接続します。
ここで、図 ③ の
Clip Vision Encode ノードには追加の crop パラメータがあることに注意してください。これは何を意味しますか?これは画像をトリミングし、そのトリミングされた画像のみをエンコードします。Center を選択すると、画像の中央部分をトリミングすることを意味します。なぜトリミングが必要なのですか?Redux モデルは正方形の画像しか受け入れられないためです。そのため、入力画像は正方形である必要があります。そうしないと、生成された画像に画像のすべての要素が含まれない可能性があります。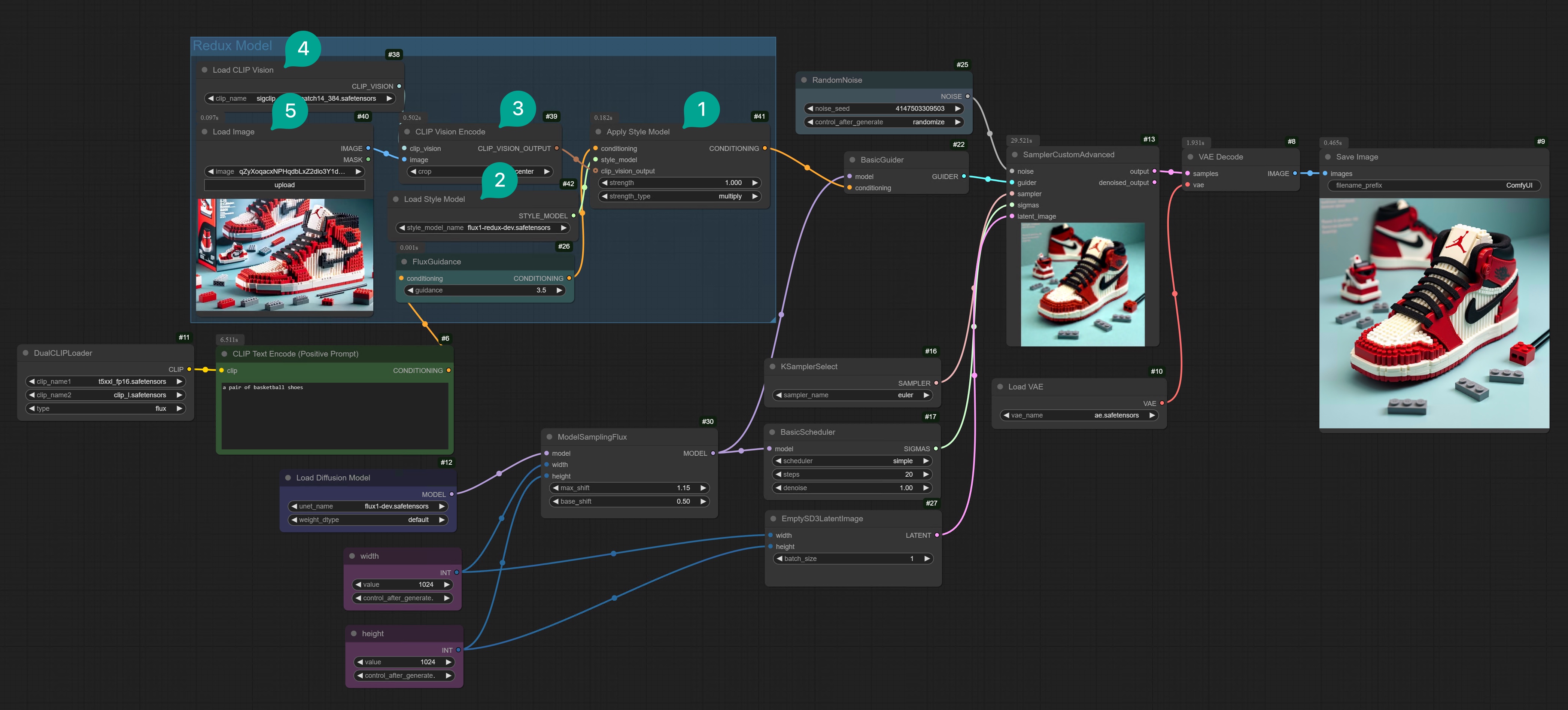
Clip Vision Encode ノードには追加の crop パラメータがあることに注意してください。これは何を意味しますか?これは画像をトリミングし、そのトリミングされた画像のみをエンコードします。Center を選択すると、画像の中央部分をトリミングすることを意味します。なぜトリミングが必要なのですか?Redux モデルは正方形の画像しか受け入れられないためです。そのため、入力画像は正方形である必要があります。そうしないと、生成された画像に画像のすべての要素が含まれない可能性があります。
このプロセスを簡単に理解すると、Flux Redux モデルを翻訳機能として使用することができます。画像内の様々な要素を Conditioning データに変換し、それを Flux モデルに入力して画像を生成します。
2.2 2 つの画像の融合
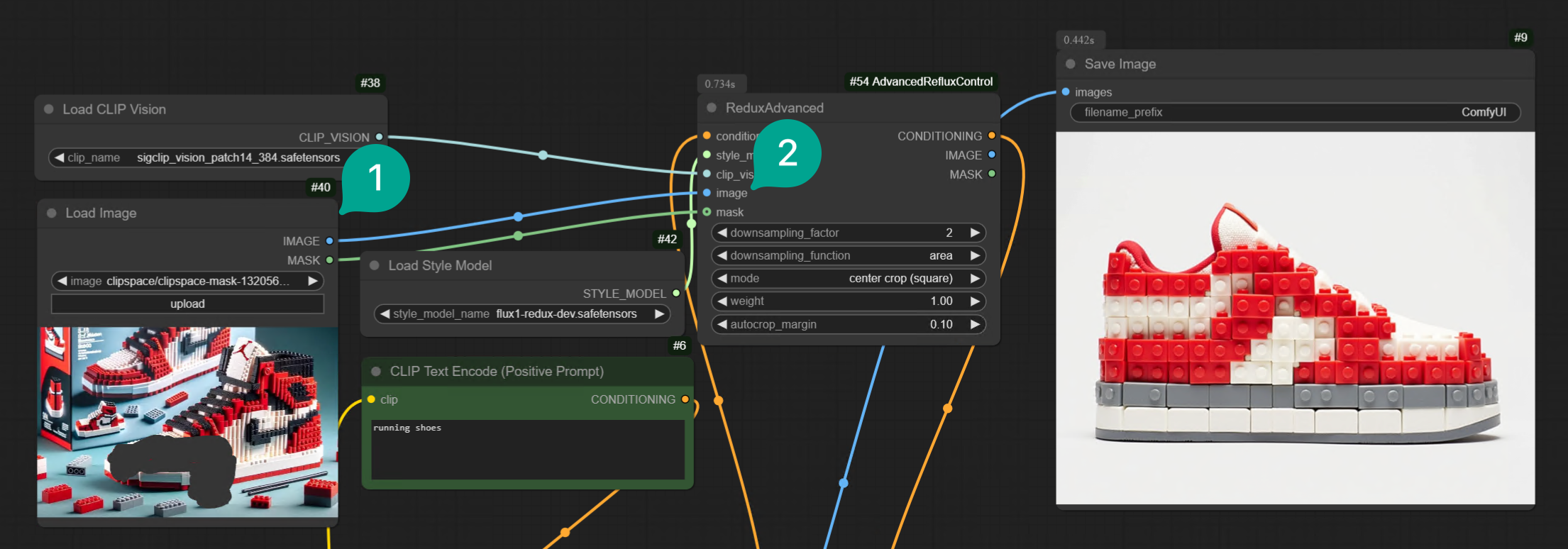
単一の画像を使用して変化を生成するだけでなく、Redux モデルを使用して 2 つの画像を融合することもできます。上記のワークフローに基づいて、Batch Images ノード (図 ①) を追加し、それを 2 番目の Load Image ノード (図 ②) に接続するだけです。
そして、融合したい 2 つの画像を選択します。例えば、ソファと森の画像を融合して、とても興味深い画像が生成されます。
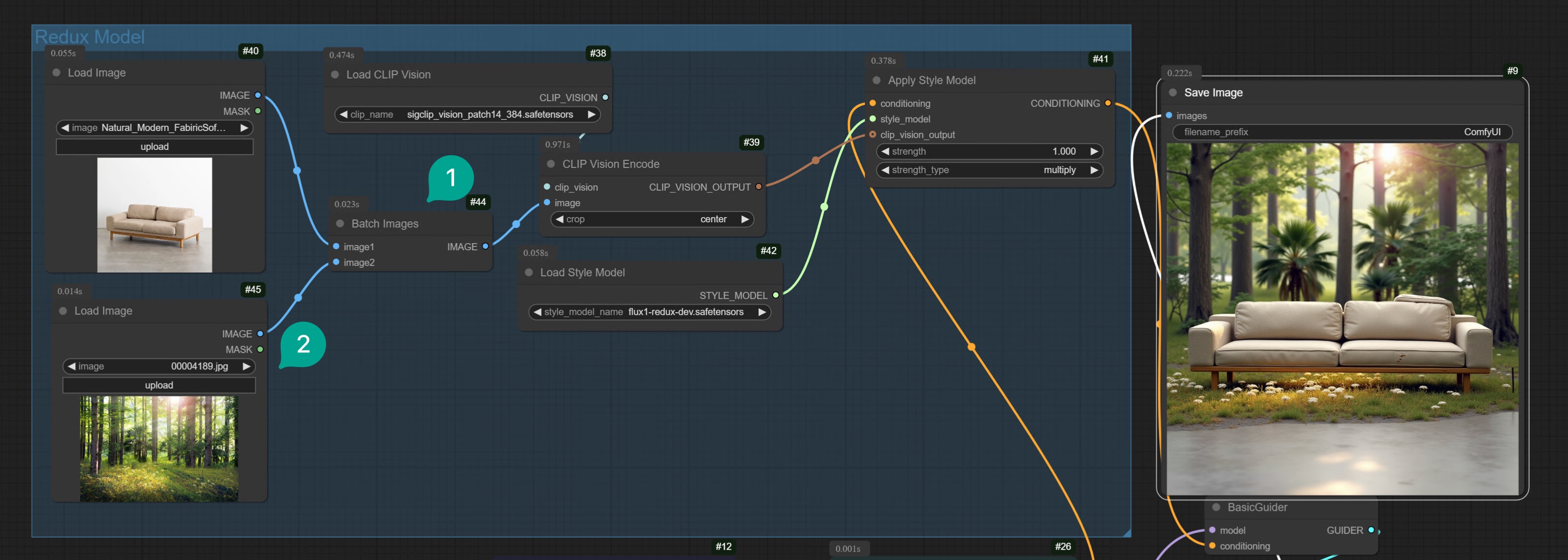
Flux ComfyUI Workflow Template
右上の Remix ボタンをクリックして ComfyUI ワークフローモードに入ります。
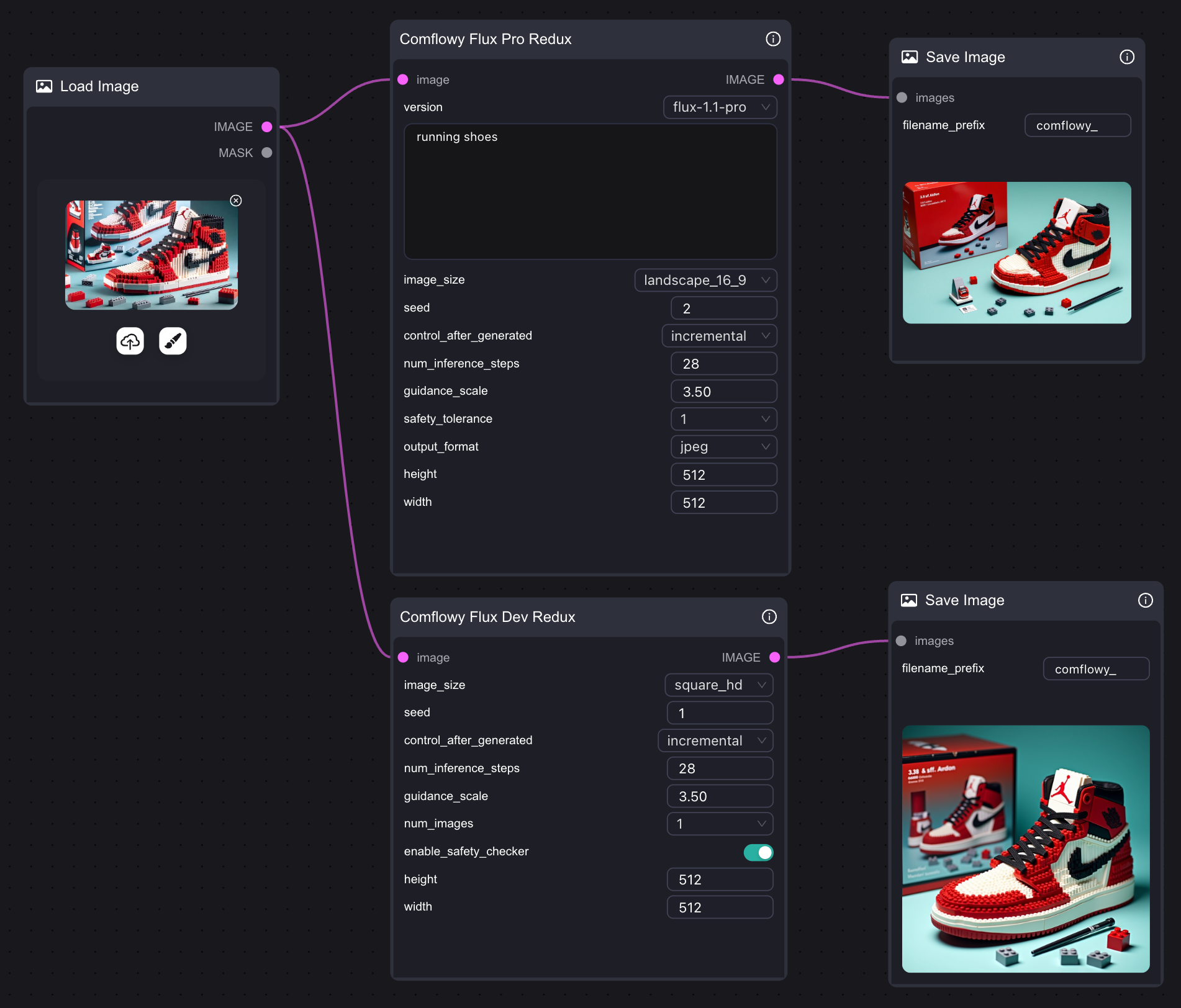
3. Flux Redux API ワークフロー
もしコンピューターの性能が十分でなく、Flux Redux モデルを実行できない場合は、ComfyUI で Comflowy の Redux API ノード を使用してみることもできます。もちろん、Comflowy で直接 Flux Redux API ノードを使用することもでき、リンク方法は非常に簡単で、1つのノードを使用するだけです。また、Flux Pro バージョンと Dev バージョンもサポートしています。このノードはAPIを使用するため、使用時に相応の料金がかかります。
4. Flux Redux の重みを減らす
上記のワークフローを使用すると、Prompt の重みが非常に低く、Prompt を介して画像の内容やスタイルを変更することができないことがあります。その理由は何でしょうか? 前述したように、Flux Redux モデルは翻訳機能です。画像内の様々な要素を Flux が理解できる Conditioning データに変換し、それを Flux モデルに入力して画像を生成します。これらの翻訳データは、あなたの Prompt に追加されます。 しかし、通常、あなたの Prompt は非常に短く、通常 255 または 512 トークンです。対照的に、Redux の Prompt は 729 トークンです。これは、元の Prompt の長さの約 3 倍です。 そのため、Prompt を介して画像の内容やスタイルをより制御したい場合は、どうすればよいでしょうか?2 つの方法があります:- Redux の重みを減らす、または Redux Prompt の長さを短くする。
- Text の重みを増加させる、または Prompt の長さを増加させる。
4.1 プラグインを使用して Redux の重みを減らす
まず、1 つ目の方法について説明します。この問題を解決するために、オープンソースの開発者がこの プラグイン を開発しました。このプラグインを使用すると、Redux モデルをより制御することができます。 このプラグインは ComfyUI Manager を介してインストールするか、Git Clone を介してインストールすることができます。詳細なインストール方法は、ComfyUI プラグインのインストール の記事を参照してください。 プラグインをインストールした後、ワークフロー内の Redux ノードグループを変更するだけです:Apply Style Modelノードを削除し、図 ① のRedux Advancedノードに置き換えます。- テキストプロンプトを変更します。
- 最後に、入力画像に似た画像が生成されますが、テキストプロンプトによって内容が制御されます。例えば、レゴスタイルのバスケットボールシューズをレゴスタイルのランニングシューズに変換しました。
- 図 ① の
Redux Advancedノードのdownsampling_factorパラメータを調整する必要があります。値が大きいほど、Image Prompt の重みが低くなります。3 はおおよそ中程度の強度です。状況に応じて異なる値の効果をテストできます。 downsampling_factorパラメータを調整するだけでなく、downsampling_functionパラメータを調整することもできます。異なるパラメータを切り替えて試してみることができます。
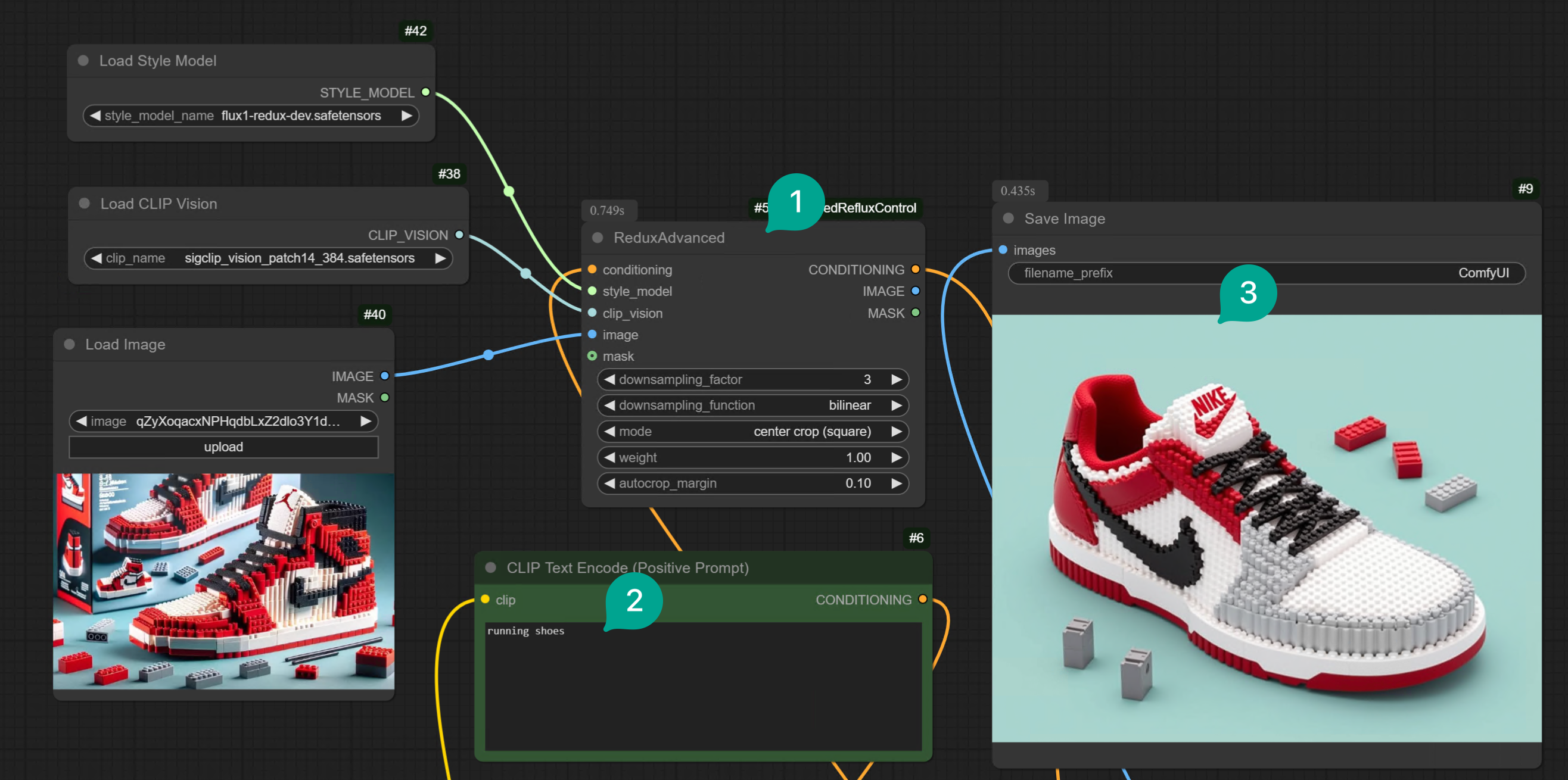
Load Image ノードの Mask 端子を Redux Advanced ノードの Mask 端子に接続し、いくつかの領域を円形にするだけです:
4.2 Text Prompt の重みを増加させる
次に、2 つ目の方法について説明します。Text の重みを増加させる、または Prompt の長さを増加させることで、Prompt の重みを増加させることができます。ワークフローは以下の通りです: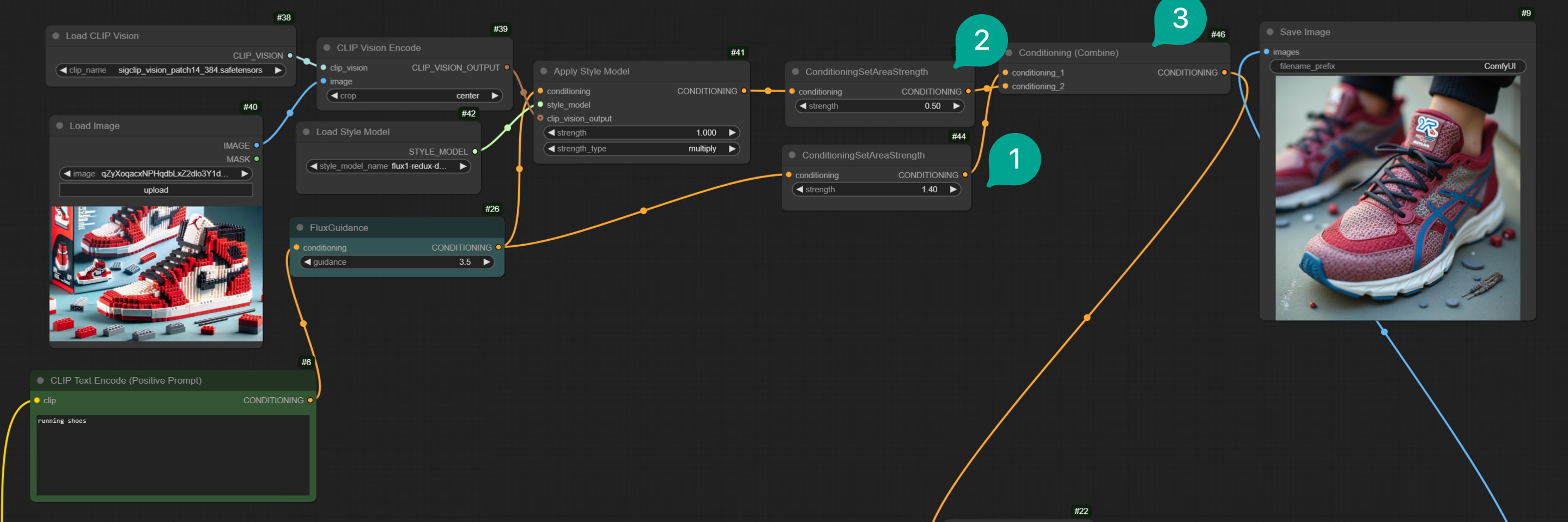
| 図 | 説明 |
|---|---|
| ① | ConditioningSetTimestepRange ノードを追加し、より区別しやすくするために Prompt Conditioning と名付けました。それを FluxGuidance ノードに接続し、開始値を 0、終了値を 0.1 に設定します。これは、最終生成過程で Text Prompt の割合が 10% に達することを意味します。Prompt の重みをより高くしたい場合は、終了値をより大きく設定します。 |
| ② | もう 1 つ ConditioningSetTimestepRange ノードを追加し、より区別しやすくするために Image Conditioning と名付けました。それを Apply Style Model ノードに接続し、開始値を 0.1、終了値を 1 に設定します。これは、最終生成過程で Image Conditioning の割合が 90% に達することを意味します。ここで、開始値は Prompt Conditioning の終了値よりも大きくなければなりません。 |
| ③ | Conditioning Combine ノードを追加し、それを Prompt Conditioning ノードと Image Conditioning ノードに接続します。Prompt Conditioning が最初の入力であることに注意してください。 |
| ④ | そして、Text Prompt に「running shoes」を入力しました。 |
| ⑤ | 生成された画像は主にランニングシューズですが、スタイルは入力画像のレゴスタイルです。 |
最終的に生成された画像があなたの要件を満たすかどうかは、
Prompt Conditioning と Image Conditioning の割合をどのように割り当てるかに依存します。要件に応じて調整してください。